



(本文作者为 半导体产业纵横,钛媒体经授权发布)
文 | 半导体产业纵横
这一周,台北国际电脑展 COMPUTEX 可谓精彩。
前一天,黄仁勋站在 GTC 大会的舞台上,出人意料的接连发布 Vare CPU、RTX Spark,宣布“ 这是 40 年来,PC 产品线首次全面重新设计。” 台下坐着微软、戴尔、惠普、联想、华硕的全球高管,他们将在今年秋季推出搭载英伟达 RTX Spark 芯片的笔记本电脑。
后一天,英特尔反手杀入英伟达的腹地,发布:数据中心 CPU 至强 6+,288 核,18A 制程;Crescent Island 数据中心 GPU,160GB 显存,风冷部署。
作为全球 GPU 霸主,英伟达杀入了英特尔的主场:CPU 和 PC;而英特尔这个 CPU 老牌王者,也盯上了英伟达的 AI 算力地盘。
AMD 倒是乐得坐山观虎斗。AMD 客户端业务高级副总裁拉胡尔· 蒂库 (Rahul Tikoo) 表示欢迎竞争。不过,之前 AMD 一直宣称自己是全球唯一一家同时具备高性能 CPU 和高性能 GPU 研发能力的半导体公司。现在好了,全球唯三。
这一周的数据中心,算是彻底乱起来了。如果只是把这场交锋解读为产品矩阵的完善或技术路线的竞争,那就太浅了。更关键的核心是:为什么两大巨头,双向奔赴彼此的主场?
复仇者联盟,归来
历史上,英伟达试图做过 PC 处理器。
2011 年,英伟达在 CES 上宣布 Project Denver,这是老黄首次公开涉足 PC 处理器领域。2012 年,微软推出 Surface RT,搭载英伟达 Tegra 3 芯片。2013 年 Surface 2 沿用 Tegra 4。这两款设备是英伟达 ARM SOC 首次进入 Windows PC 的尝试。但因为 Windows RT 生态不成熟、应用兼容性差,英伟达最终铩羽而归。
这次推出 RTX Spark 是在一个很特殊的历史节点上。
三个理由。
第一,GPU 市场的到顶了。现在英伟达在 GPU 市场的占有率超过 80%,在 AI 训练芯片市场超过 90%,数字是非常强势,但天花板肉眼可见,英伟达在这个赛道上已经没有太多增长空间。欲登更高山,必须先下山。
第二,AI PC 是全新的入口。传统 PC 的逻辑是:CPU 是核心,GPU 是配角。所有软件为 x86 设计,所有计算经过 CPU 调度。英特尔是这个生态的定义者,英伟达最多是个“ 增强显卡” 的供应商。但是 AI PC 不一样,现在 AI PC 成为了 AI 本地运行载体,这时候 GPU 的并行计算能力变的关键。英伟达既掌握着 CUDA 生态,又掌握着全球最强的 GPU 技术,还掌握着 AI 开发者最熟悉的工具链。在 AI PC 这个新赛道上,英伟达有天然的起点优势,他不需要从头建立生态,只需要把现有的 AI 能力封装成 PC 可以使用的形态。
第三,苹果的前车之鉴。苹果用 M 系列芯片证明了:当你同时掌握硬件和软件的定义权,你就能打造出竞争对手无法复制的体验。英伟达做的同样是这个模式,桌面、笔记本、工作站三件套,全部 100% Windows 兼容、100% CUDA、100% Tensor Core。按照英伟达的说法,微软会为此修改 Windows 任务栏用户界面。上百家软件供应商和游戏开发商同意开发 Arm 移植版。Adobe 正在“ 从底层重构”Photoshop 和 Premiere 来适配 RTX Spark。

这一次,黄仁勋显然是有备而来,组合了一个“ 复仇者联盟”:微软、联发科、ARM。联发科,长期主导入门级消费芯片市场,高端始终难以突破,PC 芯片领域一直徘徊在中低端梯队。Arm,在移动端称王,但是 PC 市场被 X86 垄断,高通也和微软带头做 Windows on Arm,但 Windows 用户对 Arm PC 一直有顾虑。微软,Copilot+ PC 已经把 AI 电脑的概念打了出来,但目前很多 AI PC 体验仍然偏轻,云端 Copilot 到本地 Copilot 之间缺一座桥。
英伟达的加入,刚好补上了这块短板。AI 性能高达 1 PetaFLOP,128GB 统一内存,可本地运行 120 亿参数、上下文长度达 100 万 token 的大语言模型。
1 PetaFLOP 是什么概念?英伟达 2020 年卖的数据中心 GPU A100 的 FP16 峰值是 312 TFLOPS。一颗笔记本芯片,四年后翻了不止三倍。这对微软来说是 Windows AI PC 体验质变的机会,对 ARM 是打穿 x86 垄断的机会,对联发科是切入高端 PC 市场的机会。四方的利益,在 AI PC 上形成了交集。但很微妙的是,在数据中心市场,英伟达最大的客户是:Azure、AWS、Google Cloud。英伟达是“ 卖铲人”,把产品卖给所有人。RTX Spark 的核心卖点是本地 AI 算力,1 PetaFLOP 的 AI 推理能力,本地跑模型、本地跑 Agent。如果本地算力足够强,用户为什么还要上云?为什么还要 Azure?黄仁勋在帮微软站台的同时,其实也在松动微软云业务的地基。这就是今天科技行业悖论的地方,所有人都是合作伙伴,所有人也都是潜在对手。
再来看英伟达的 Vare CPU。英伟达为什么要花费巨大资源自研数据中心 CPU?黄仁勋在发布 Vera CPU 时说了一句话,被业界反复引用:“CPU 不再仅仅是支持模型运行;它正在驱动模型。” 这句话背后,是英伟达对 AI 时代计算架构的重新理解。
英伟达做 Vera CPU,不是为了抢英特尔传统 CPU 的市场,而是不能让 CPU 成为自己 GPU 的绊脚石。在智能体 AI 工作负载中,CPU 需要频繁调度 GPU 资源、处理超长上下文、管理海量的工具调用。这些任务的延迟要求是纳秒级的,如果 CPU 响应慢,整个系统的吞吐量都会下降。现在的瓶颈在于:任务编排、工具调用、超长上下文管理、海量状态维护,这些全都压在 CPU 上,PU 集群价值数百亿美元,但如果 CPU 跟不上调度节奏,这些 GPU 会因为等待任务分配而大量闲置。
算力越强,浪费越多。所以,Vera CPU 定位很清晰:不是 x86 的替代品,而是“ 为 Agent 制造的 CPU”。我们来看 Vare CPU 的设计重点:第一,极致带宽,1.2TB/s 内存带宽,比高端 x86 CPU 高出 2-3 倍;第二,超低延迟,通过 NVLink 与 GPU 直接互联,避免 PCIe 瓶颈;第三,高能效,LPDDR5X 内存,功耗比传统 DDR5 低 50%。
英伟达不会让自己的算力帝国被一颗 CPU 卡住。老黄的意思很明显:未来的数据中心建立在“ 英伟达 inside” 的基础上,而不是“x86 inside” 的基础上。Vera CPU 目前已进入全面量产阶段,预计今年第三季度正式投产。OpenAI、Anthropic、SpaceX 已确认成为首批部署客户。英伟达预计,本财年 CPU 营收将达到 200 亿美元,这意味着英伟达将在 CPU 市场与 AMD、英特尔形成正面竞争。
数据中心,才是主战场
陈立武接英特尔 CEO 的时候,这家公司正陷在泥潭里。制程工艺被台积电甩开,股价低迷,核心员工流失。他需要做的事情很多,但他必须先回答一个问题:英特尔的核心价值到底是什么?陈立武在 COMPUTEX 上说了一个核心的观点:CPU(尤其是 x86 架构 CPU) 是整个算力体系的基石。英特尔将在四个核心领域创造万亿美元的价值,分别是,个人电脑、边缘市场和代理式 AI、数据中心、新兴的智能中心。
这次,英特尔亮相的数据中心 CPU 和 GPU,打的是是英伟达的腹地—— 数据中心。

首先来看英特尔的至强 6+。CPU 本来就是英特尔的主场,几十年的 x86 生态、数十年的客户关系、无数企业级软件为至强优化,这是 AMD 和英伟达都难以复制的优势。
至强 6+采用 288 核,18A 制程,超大规模并行设计。配备最高 576MB 三级缓存,面向云原生、AgenticAI 和网络密集型等负载需求,可以提供更高的能效和更稳定的持续性能。单个液冷机架占用 32U 计算空间,就能提供 36864 个核心;机架功耗仅约 100kW,足以承载高密度智能体部署。与过往同等性能的服务器机架相比,功耗已经大幅降低。据新华三相关工作人员介绍,新华三与英特尔合作,推出了 UniServer R6900 G7 AI 训推一体化方案,由于至强 6+的多核优势,方案采用纯 CPU 部署 35B 参数大语言模型,能够实现价格仅为常规 GPU 方案的一半。在至强 6+之后,英特尔又亮出了 Crescent Island。具体来看,Crescent Island 基于 Xe3P 微架构,属于 Xe 系列高性能方向,采用 LPDDR5X 显存 (不是 HBM),最高达到 480GB,同时 350W 风冷部署 (不是液冷),主打能效比。英特尔的核心策略是:避开英伟达在高端训练市场的绝对优势,选择推理赛道作为突破口。
这是英特尔明智的地方,不直接做高端训练 GPU 与英伟达 GB300 正面竞争。
为什么?答案很简单:挑战太大。
英伟达有完整的 GPU 产品线,包括:H100、H200 和 H20,以及 Blackwell 架构的 GB200 和 GB300。英伟达的优势建立在三个基础上:第一,CUDA 生态。所有训练框架 (PyTorch、TensorFlow、JAX) 和推理框架 (TensorRT、vLLM、TGI) 都针对英伟达 GPU 做了深度优化。第二,高带宽显存。GB300 的 HBM3e 显存带宽达 8TB/s,GB300 集群可支撑万亿参数大模型的实时训练。第三,软件栈完整性。从驱动到框架到部署工具,英伟达提供一站式解决方案。
高端训练 GPU 的核心竞争要素从来不是硬件参数,而是软件生态。这种生态壁垒,不是英特尔花几年时间就能建立的。Gaudi 系列的表现已经证明了这一点。尽管硬件规格不差,但软件生态的短板让 Gaudi 在市场上始终未能形成气候。
这次英特尔的战略有点类似:农村包围城市。英特尔选择推理赛道的原因很很明显,训练市场的窗口已经关闭了。英伟达和 AMD 建立了足够深的护城河,但是推理市场随着大模型落地带来了海量的中小规模推理需求,这些需求对成本敏感、对部署简便性要求高,恰好是 Crescent Island 的用武之地。我们回头来看 Crescent Island 的关键词:480GB LPDDR5X 显存、350W 热设计功耗、风冷部署。解决的正是企业客户最关心的问题:功耗、散热、部署成本。
如果说,英伟达的推理 GPU 是高端市场的低成本方案,用性能收取相对合理的价格。那么,英特尔的 Crescent Island 是低端市场的高端方案。用相对低的功耗和部署成本,提供“ 足够用” 的 AI 推理能力。英特尔赌的是当推理成为 AI 应用的主流场景时,今天积累的市场份额将转化为更大的话语权。
AMD 怎么办?
在本周的这场交锋里,AMD 没有出现,但是 AMD 也在暗中经历价值重估。
2026 年第一季度,AMD 交出了一份令人惊艳的财报:营收 103 亿美元,同比增长 38%,净利润 13.8 亿美元,同比增长 95%。数据中心业务营收 58 亿美元,同比暴增 57%,占公司总营收的比例已上升至约 57%。
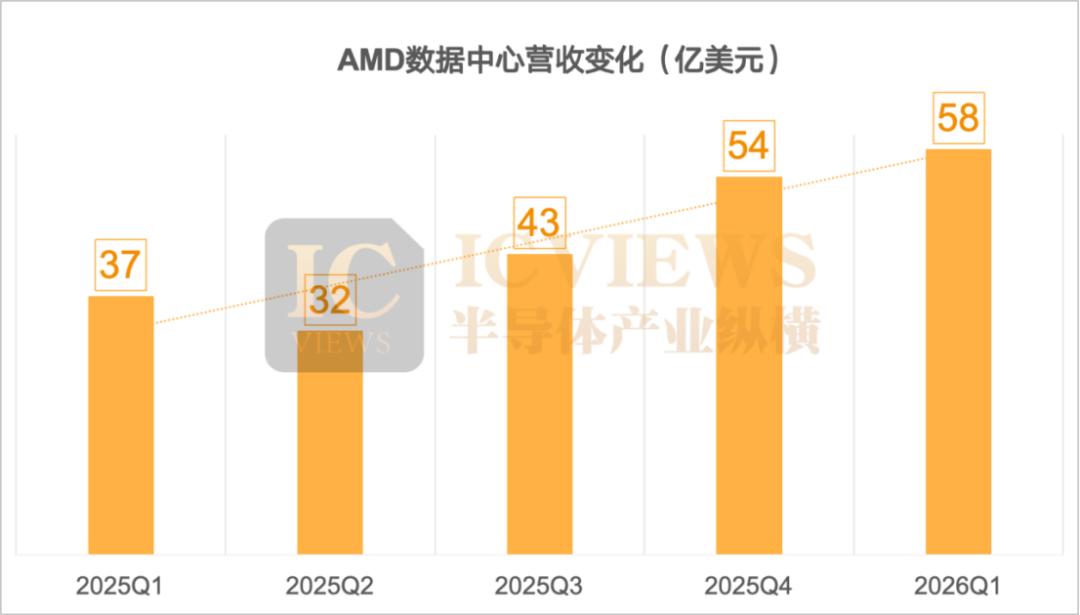
从 2025 年 Q1 到 2026 年 Q1,AMD 数据中心业务走过了一条教科书式的加速曲线:37 亿美元→43 亿美元→58 亿美元。AMD 数据中心业务的增长由两条腿驱动:EPYC 服务器 CPU 和 Instinct GPU 加速卡。两者在 2025 至 2026 年的 AI 基础设施投资潮中均获得了强劲的市场需求。Oracle Cloud、谷歌云相继宣布采用第五代 EPYC 处理器构建新一代实例;Instinct GPU 方面,MI300 系列在 AI 推理和训练市场中持续扩大客户基础。AMD 在 2026 年最具战略意义的产品动作,是一个名为 Helios 的全机柜 AI 系统。这套系统被定位为直接对标英伟达 Grace Blackwell 和 Vera Rubin 系统的竞品—— 后者的整机柜售价超过 300 万美元。
Lisa Su 在财报电话会上说了一句超出常规财报措辞尺度的话:“AMD 有信心 2027 年实现数据中心人工智能业务年营收数百亿美元。”

这是一个相当激进的承诺。但如果 AMD 能够将 Helios 系统成功推向市场,并在 ROCm 软件生态上持续缩小与 CUDA 的差距,这个承诺并非不可能实现。
算力新秩序的黎明
2026 年的数据中心芯片市场,呈现出一幅前所未有的图景。
英伟达从 GPU 霸主向系统级算力平台供应商转型,携 RTX Spark 和 Vera CPU 双线进攻。英特尔以至强 6+和 Crescent Island 反击,同时在制程工艺和架构设计上寻求突破。AMD 在 CPU 和 GPU 双线并进,以 Helios 和 ROCm 生态为抓手,试图在两强之间开辟自己的生态位。
这是一场关乎未来十年数字经济主导权的交锋。谁能赢得智能体 AI 时代的算力基础设施,谁就能在下一个计算时代占据核心位置。
目前来看,但变数依然存在。芯片通胀正在推高整个产业成本,供应链紧张态势短期难以缓解。Arm 与 x86 的架构之争鹿死谁手,尚未可知。芯片政策变数和中国本土芯片厂商的崛起,将为这场比拼增添更多不确定性。
唯一确定的是,在 AI 变幻莫测的时代,没有厂商敢继续安于一隅。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App