


(本文作者为 市值水晶,钛媒体经授权发布)
文 | 市值水晶
反复拉扯,这是壁仞科技当下的股价走势。
6 月 8 日,壁仞科技正式纳入港股通名单,股价当天一度逆市涨超 13%。对于这家上市不到半年的国产 GPU 公司来说,这意味着南向资金的闸门打开,流动性和机构持仓比例有望进一步提升。
就在两个多月前,壁仞科技交出了港股上市后的首份年报,业绩表现十分亮眼:2025 年全年营收 10.35 亿元,同比增长 207.2%;毛利 5.57 亿元,同比增长 210.8%。
但另一边,是壁仞科技高达 14.76 亿元的研发开支,同比增速高达 78.5%,经调整年内亏损 8.74 亿元,存货余额则来到 9.49 亿元,换言之,在迭代速度极快的 AI 芯片赛道,囤积的存货若无法及时售出,将面临减值风险。
这就是壁仞科技首份年报传递的核心信号:在营收激增的同时,应收账款周转天数在拉长,真金白银的落袋还未跟上。
它证明壁仞不仅能设计 GPU,还能把 GPU 卖出去。而没能证明的一点是,在当前特定时间窗口的红利下,壁仞科技能否做实国产替代故事,持续高质量地赚钱。
01 与时间赛跑
要理解壁仞科技亏损的本质,要先看一张跨越三年的经调整利润表。
2023 年,壁仞科技经调整净亏损是约 10.5 亿元;2024 年收窄至约 7.7 亿元;2025 年,又回升到 8.74 亿元。
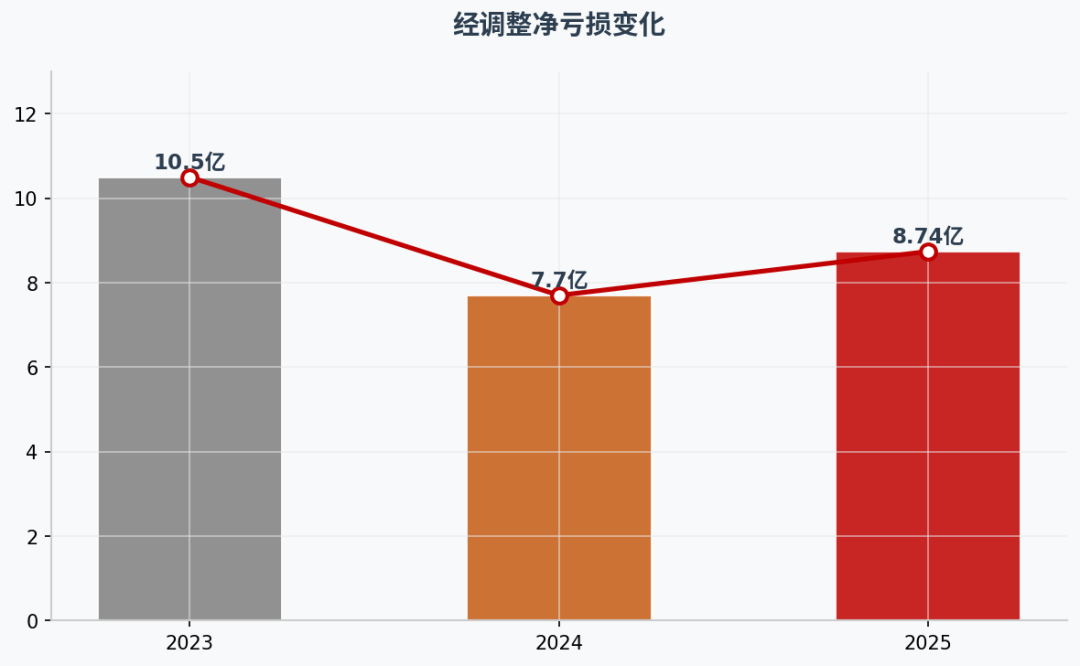
表面看,企业亏损并没有随着收入高速增长而持续收窄,2025 年反而比 2024 年多亏了 1 个亿。
背后是研发的高额投入,2025 年壁仞科技的 14.76 亿元研发开支中,相当一部分投向了下一代旗舰芯片 BR20X 的前期开发—— 架构设计、流片准备、软件栈适配。

换句话说,财报中同期亏损几乎全部来自研发投入,赚来的钱都砸进下一代芯片研发还是不够。
这是一场典型的芯片行业"跨代投资"游戏。每一代芯片的研发投入必须提前两年左右启动,在财务上则表现为,上一代产品的收入往往要在研发启动之后才开始规模化放量。
结果是财报中,投资者看到的是一个预支未来的利润表—— 今天的收入在为昨天的研发买单,今天的研发又在赌明天的市场。
在芯片行业的初创阶段,这样的投入模式并非不可接受。
GPU 芯片设计是一个典型的前期投入密集、后期放量盈利的行业。英伟达曾在 CUDA 生态成型前有过研发费用率高增长的时间段。
但当时的英伟达已经有了成熟的 GeForce 游戏显卡业务作为现金流底座。壁仞则缺少这样的底气,它的全部收入都来自 AI 算力市场,而 AI 算力市场的客户只看性价比。
这个游戏的残酷之处在于,壁仞科技当前的高增长和高毛利,很大程度上建立在一个不可持续的"时间红利"之上。
壁仞科技的崛起,源于多因素的共振,其中核心的一环是英伟达的缺席产生的市场真空,留下的市场空白需要填补。同期华为昇腾的产能不足以满足市场需求。这也是壁仞科技被推上资本市场,上市首日市值破千亿的核心动力。
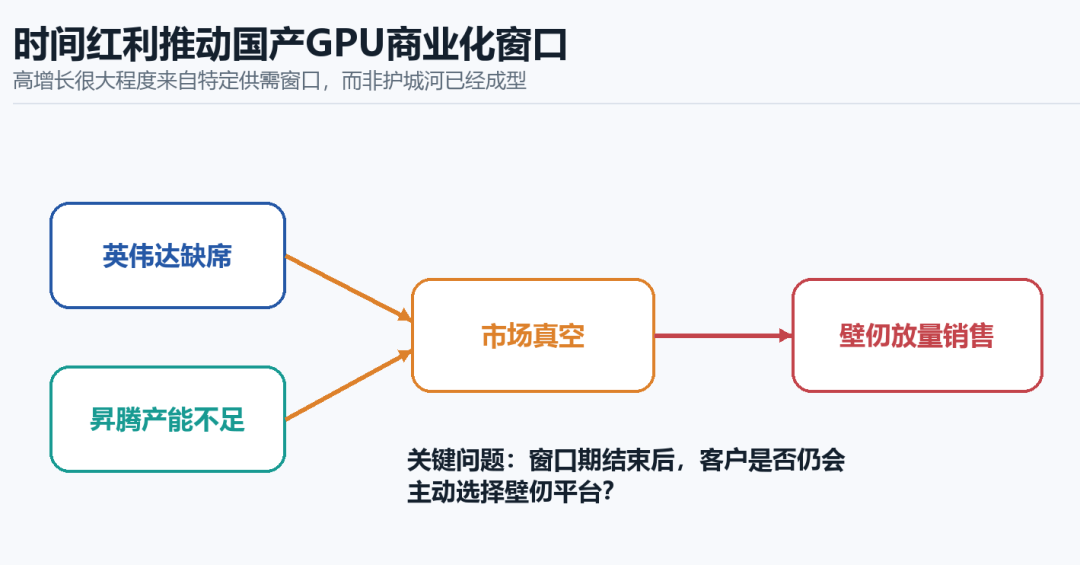
但相较头部玩家,壁仞科技还少了太多手牌。
从产品性能看,昇腾遵循“ 一年一代” 的节奏,已形成覆盖训练和推理的繁荣产品矩阵,而壁仞的当前主力产品,仍然是 2023 年量产的 BR106 和 2025 年推出的 BR166。
在年度财报中,壁仞科技提到,企业将通过优化制程工艺和封装方案来降低单位成本。这将是壁仞科技的下一步战略重心—— 在“ 鲶鱼” 回归之前有必要打通商业闭环,争取更多核心客户将训练集群的算力底座迁移到壁仞平台中,要让客户从不得不选,切换到主动选择。
02 离生态护城河有多远
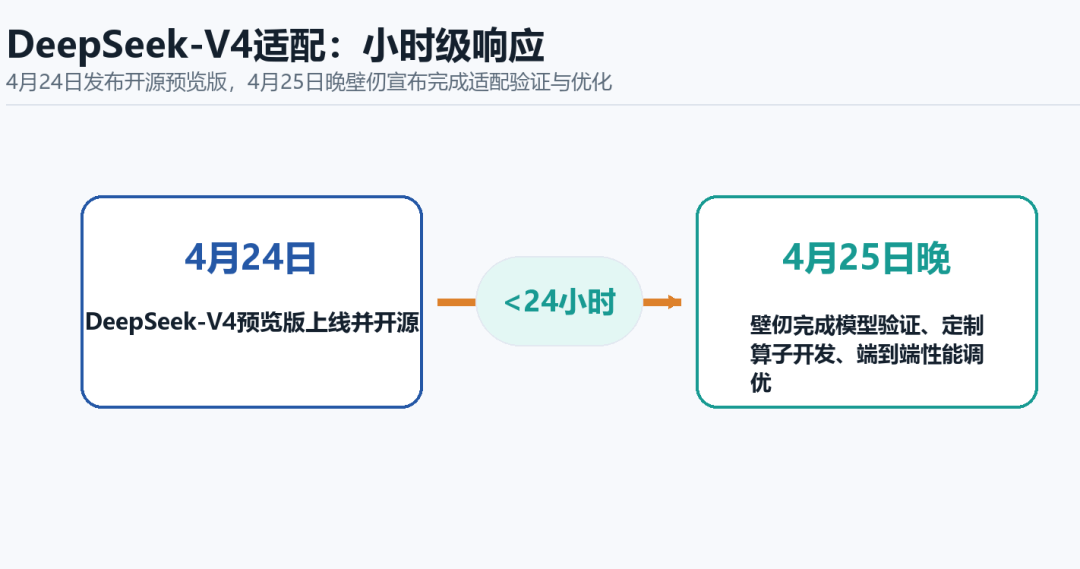
2026 年 4 月 24 日,深度求索团队在官网宣布:DeepSeek-V4 预览版正式上线并开源。这是继 V3 引发全球关注之后,DeepSeek 的又一次深夜炸弹式发布。整个 AI 行业迅速进入适配竞速赛—— 谁先跑通 V4,谁就能在推理部署市场上占据先机。
不到 24 小时,壁仞科技的工程师们已经动起来了。
4 月 25 日晚,壁仞科技宣布完成 DeepSeek-V4 在旗舰 GPU 壁砺 166 系列上的适配验证与优化,包括模型验证跑通、定制化算子开发及端到端性能调优等。
一天之内跑通全球最受瞩目的开源大模型—— 这对壁仞的软件栈团队来说,是一次不容闪失的亮剑。证明 BIRENSUPA 的响应速度已经达到了可以用小时为单位计算的水平。
但跑通不意味着跑好。
GPU 行业的竞争,表面上是算力参数的比拼,如显存带宽、制程工艺。但这些只是入场券。真正的壁垒,在软件生态。
英伟达的护城河从来不是单卡算力,而是 CUDA。过去十几年的时间里,海量开发者基于 CUDA 编写了数百万个 GPU 加速应用程序。
从深度学习框架到科学计算,CUDA 是事实上的行业标准。替换一张 GPU 卡容易,替换基于 CUDA 的整个软件栈,成本高到绝大多数企业不会去算。
对此壁仞科技投入了大量资源构建自己的软件生态。
在自研软件开发平台 BIRENSUPA 中,壁仞科技将快速适配与广泛兼容两个特性做到极致,借助自研的智能体系统 AIModelMaster 和 SUPACODE 多智能体编排平台,壁仞科技已经对多款国内前沿模型完成小时级适配。
这份“ 当天搞定” 名单除了 DeepSeek-V4,还包含一批国内知名的前沿模型,如 Kimi K2.6、智谱 GLM-5.1、混元 Hy3 preview、阶跃星辰 Step 3.5 Flash 等等。
这是一套主打兼容性与替代能力的打法,强调在最短时间内覆盖主流模型,并不断拓展前沿应用。在软件栈层面,壁仞能深度兼容 PyTorch、vLLM、SGLang、Diffusers 等主流 AI 框架,让开发者将项目自由迁移。
但解决了从 0 到 1 的问题,还面临从 1 到 10 的问题。开发者把模型从 CUDA 迁移到 BIRENSUPA 之后,需要功能更丰富的调试工具,甚至是现成的错误解答贴。当一个 AI 公司的工程团队面对成百上千个这样的小问题时,"迁移"的隐性成本就累积到了足以劝退核心业务的程度。
这也是壁仞科技收入结构单一的原因。2025 年年报显示,壁仞科技的智能计算解决方案收入占比高达 99.4%,软件和服务收入几乎可以忽略不计。
依赖硬件销售的一次性博弈,而持续性收益乏力,这是壁仞科技的难题所在。相较英伟达 CUDA 企业版授权、DGX Cloud 云服务等收入,壁仞仍然缺少这一层业务地基。
换句话说,核心训练用英伟达,边缘推理用壁仞。这样的客户习惯不改变,壁仞就拿不到自己的定价权。
03 爬过生态鸿沟
2025 年 7 月 28 日的 WAIC 论坛现场,壁仞科技与上海仪电、曦智科技、中兴通讯三家企业联合发布了光跃 LightSphere X—— 国内首个光互连光交换 GPU 超节点。
这是壁仞科技从卖单卡向卖集群迈出的关键一步。光跃 LightSphere X 能通过光信号而非传统电信号,将众多计算芯片高效连接成一个超级计算单元,突破单机柜功耗和距离限制,支持万卡级弹性扩展。
但背后仍然有急需追赶的技术劣势。光跃 LightSphere X 在创新性上取得了突破,但英伟达的绝对优势在于其整个系统的成熟度和精密的协同性。
集群效率的竞争不只是硬件的比拼。决定一个千卡级训练集群真正有效算力输出的,往往不是单卡峰值 TFLOPS,而是卡间通信延迟、故障恢复速度、负载均衡策略、梯度同步效率这些软实力。
以卡间通信效率为例,英伟达不仅通过 NVLink+NVSwitch 构建无阻塞网络,实现了单个机架内 72 颗 GPU 全连接,同时提供 NCCL、Mission control 等全栈工具链,能在不重启节点的情况下确保故障 GPU 隔离乃至重置。
相比英伟达从芯片、互联、服务器、软件调度到冷却方案的全栈自研方案,光跃 LightSphere X 是一个联合舰队—— 曦智科技的分布式光交换技术、壁仞的 GPU 液冷模组、中兴的国产服务器、仪电的智算云平台,四家企业各司其职。
这在技术协同上没有问题,但在集成度、交付效率和长期维护上,联合方案天然比全栈自研方案多了一层协调成本。
这也是资本市场对壁仞科技估值持续分歧的根源所在。
如果用英伟达的坐标系来审视,壁仞科技显然高估了,10.35 亿元年收入对应超过 1300 亿港币的总市值,市销率超过百倍。
作为对比,英伟达近期的市销率约在 20 倍。百倍市销率意味着,壁仞科技需要在未来几年内将收入提升至少一个数量级,才能消化当前估值。
但如果用国产替代的坐标系来审视,壁仞科技的前景还要更大。IDC 数据显示,得益于 AI 应用的全民普及,以及政策的持续加码,2026 年中国 AI 算力市场规模将达到 337 亿美元。
在一个高速成长的市场中,最先跑出来的国产 GPU 厂商理应享有成长溢价。
前提是,壁仞能不能在缺货红利消退之前,建立起属于自己的不可替代性。包括软件生态的成熟度,服务收入的可观占比,和商业模式的闭环。
但现状是,壁仞在生态、软件、服务收入占比领域全部处于初级阶段。只有建立可持续的收入模式,降低研发费用率,构筑留住开发者的软件生态,壁仞才有接近下一个叙事的机会。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App