



文 | 半导体产业纵横
过去几年,国产 AI 芯片始终活跃在一个相对安全、也相对边缘的位置—— 推理侧。
在政务、金融、安防、工业质检等场景中,国产芯片凭借成本可控、供应稳定等优势,逐步完成了从“ 可用” 到“ 好用” 的过程。但在 AI 训练这一算力金字塔顶端,国产芯片长期缺席,或者只能参与边缘性任务。
这一格局,正在发生改变。2026 年,将成为“ 国产 AI 芯片训练落地元年”。但这一步,绝非简单升级,而是一场系统工程级别的跨越。
01
训练与推理有何区别?
在大众语境中,“AI 算力” 往往被视作一个整体,但在工程实践中,训练与推理几乎是两种完全不同的工作负载。
训练的核心是让 AI 模型“ 学会知识”,具体而言,是通过海量带标签样本,经过特定算法迭代,求解出机器学习模型最优参数的过程。这一阶段需要海量数据的持续投喂、数十亿至万亿级参数的动态更新,以及数周乃至数月的不间断运行,追求的是吞吐量与规模化运算效率。
这意味着训练芯片不仅要具备强悍的算力,还需配备极高的显存带宽、高效的分布式通信能力,以及万卡级集群规模下的稳定性。训练过程可进一步细分为预训练与后训练两个阶段:预训练依托海量无标注或弱标注数据,通过大规模反复迭代计算优化模型参数,最小化预测误差,最终形成具备通用生成能力的基础大模型,对芯片的计算性能、互连通信能力及通用性提出极高要求;后训练又称微调、优化阶段,基于通用大模型,借助标注专业数据集对输出层参数进行量化、剪枝等优化,通过强化学习强化特定领域适配能力,虽计算量不及预训练,但随着行业化需求提升,其在全流程中的权重正持续增加。
与训练形成鲜明对比,推理是模型“ 运用知识” 的阶段,需要依托已训练完成的模型参数,对新输入数据进行预测、生成响应,是 AI 技术落地解决实际问题的核心环节。相较于训练,推理更侧重速度、能效比、响应延迟与成本控制,其部署场景覆盖云服务、边缘节点乃至终端设备,对稳定性与能效比的诉求远高于峰值算力。这种特性使得推理过程无需经历漫长的迭代训练,可直接调用成熟模型完成分析预测,在海量数据处理与实时响应场景中具备显著高效性。
大模型的发展遵循 Scaling Law 的经验公式,即模型参数量、数据量以及计算资源的增长能得到更好的模型智能。在通用基础大模型发展阶段,大模型向更大参数方向不断演化,预训练阶段的数据量呈指数级增长,GPU 作为算力硬件的核心在预训练市场经历了爆发增长。根据中国信通院 《中国算力发展白皮书 (2023)》,GPT-3 的模型参数约为 1,746 亿个,而 GPT-4 的模型参数约达到了约 1.8 万亿个,训练算力需求上升了 68 倍。此外,xAI 发布的 Grok-3 使用 20 万卡训练芯片集群带来模型性能提升亦证明了预训练 Scaling Law 将长期成为人工智能发展的基石。
更值得关注的是,训练算力存在“ 边际效益递减” 的天花板。对于稠密架构大模型,当参数从千亿级向万亿级跨越时,算力需求呈超线性增长,指数级攀升的成本压力,让从头训练大模型成为少数科技巨头的“ 专属游戏”。
凭借高算力门槛,国际领先厂商英伟达的产品一直以来都是人工智能训练端的首选,占据了 AI 训练市场 90% 以上份额,其 Blackwell 架构支持 1.8 万亿参数模型训练,且 NVLink 6 技术实现 72 卡集群无缝互联。而推理端 (尤其是边缘端、终端推理) 对芯片性能要求较训练端低,因此推理芯片市场百花齐放,各类芯片均占有一席之地。
由于中国 AI 芯片市场起步较晚,国产厂商通常从门槛相对较低的推理端切入市场,目前已取得阶段性成果;而训练端的国产化率仍相对较低。在海外高性能芯片出口管制不断升级的背景下,拥有高性能计算能力、产品可有效应用于训练端的国产厂商将充分受益。
02
国产算力走向训练,难在那里?
从“ 能推理” 到“ 能训练”,表面看是性能维度的小幅提升,实则是跨越全技术栈的深度重构,核心面临技术突破与商业闭环两大挑战,考验的是企业的综合攻坚能力。
技术层面,核心矛盾已从单一芯片的纸面参数竞争,转向万卡级集群的互联瓶颈突破,最终目标是提升模型算力利用率 (MFU)。硬件端,单卡性能的提升已无法满足大规模训练需求,分布式并行成为必由之路——Scale Up 通过增加单服务器 GPU 数量构建超节点,Scale Out 通过扩容服务器规模搭建分布式集群,谷歌、Meta、微软等海外大厂已率先布局,如谷歌 A3 虚拟机搭载 2.6 万块英伟达 H100 GPU,同时基于自研芯片搭建 8960 卡 TPUv5p 集群,通过规模化集群优势优化服务架构。而国产厂商虽在单卡性能上实现突破,但在集群协同能力上仍与海外存在差距。
软件端,单纯兼容 CUDA 生态的路径在高强度训练场景中已暴露瓶颈,构建原生、高效的自主软件生态成为必然选择。随着大模型参数量与算法复杂度提升,训练任务对计算系统的通信能力要求持续升级,千卡、万卡级智算集群成为标配,而国内具备完整训练芯片部署能力的厂商寥寥无几。其中,华为海思凭借长期技术积淀、全栈协同优势及丰富的人才与客户储备,在国产训练芯片领域建立了显著领先地位。
技术之外,市场用最朴素的逻辑投票:稳定性与总拥有成本 (TCO),这两大维度构成了对国产训练芯片的核心拷问:
其一为应用稳定性,长达数月的训练任务对芯片平均无故障时间 (MTBF) 提出极致要求,一次意外中断就可能造成数百万沉没成本。这也是当前智算中心普遍采用“ 异构部署” 策略的核心原因—— 通过英伟达芯片保障核心基座模型的稳定运行,同时用国产芯片在垂类模型微调、推理等场景中迭代优化、积累信任,推动国产算力从“ 敢用” 向“ 愿用” 跨越,而实战落地是唯一的破局路径。

其二为产业体系升维。客户最终采购的并非 PetaFLOPS 这类冰冷的性能参数,而是稳定高效的 AI 生产力。这要求国产厂商完成从“ 单一芯片供应商” 到“ 全栈算力解决方案服务商” 的转型,具备从供电、液冷等基础设施到软件调优、运维支持的全链条服务能力,交付一套高性能、高可靠的“ 算力动力总成”。
03
国产 AI 芯片从推理走向训练
国产芯片在训练场景的落地,并非一蹴而就的爆发,而是政策驱动与技术迭代共同作用的结果,早在去年就已显现端倪。2025 年 8 月 21 日,DeepSeek 曾表示,新版本采用了一项针对国产芯片而设计的技术,能够实现性能优化,并加快处理速度。
政策层面的支撑更为明确:2025 年 5 月,美国 BIS 发布 《关于可能适用于先进计算芯片及其他用于训练 AI 模型商品的管制的政策声明》《关于通用禁令 10(GP10) 对中华人民共和国 (PRC) 先进计算芯片适用的指南》《关于防止先进计算芯片转移的行业指南》,从 AI 芯片的使用范围、供应链制裁等角度进一步加强了对先进 AI 芯片和相关技术的出口管制,将出口管制风险进一步延伸至产业链的各个参与方。地缘政治倒逼相关国内客户使用国产 GPU 产品,在一定程度上帮助国产 GPU 厂商与国内客户和供应商建立密切联系,进而快速实现技术和产品迭代升级。
而且近期,工信部联合 7 部门出台 《“ 人工智能+制造” 专项行动实施意见》 明确提出,支持突破高端训练芯片、端侧推理芯片、人工智能服务器、高速互联、智算云操作系统等关键技术。
多重因素叠加下,2026 年成为国产 AI 芯片训练落地的关键元年。
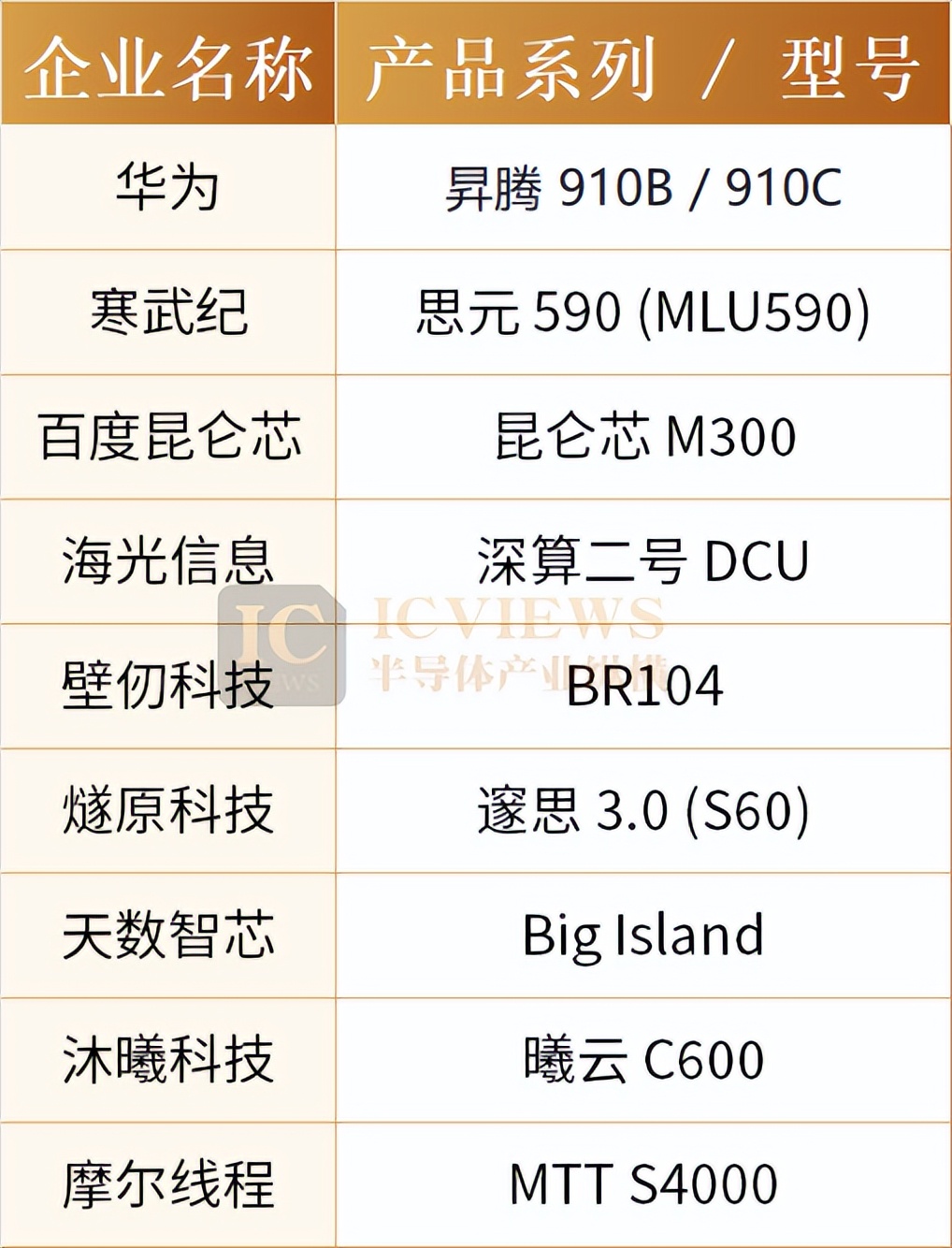
今年以来,一批基于国产芯片训练的 AI 大模型密集落地,标志着国产算力在训练场景的实战能力得到验证。
2026 年 1 月 14 日,智谱联合华为开源新一代图像生成模型 GLM-Image,开源后 24 小时内登顶全球 AI 开源社区 Hugging Face Trending 榜单榜首。该模型基于华为昇腾 Atlas 800T A2 设备与昇思 MindSpore AI 框架,完成从数据处理到模型训练的全流程闭环,是首个依托国产芯片实现全程训练的 SOTA(当前最高水平) 多模态模型,首次让国产芯片训练的模型站上国际顶端舞台,印证了我国 AI 模型端到端自主研发能力的突破,引发全球 AI 圈、产业界与资本市场的广泛关注。
1 月 13 日,摩尔线程与北京智源人工智能研究院达成突破,依托 MTT S5000 千卡智算集群与 FlagOS-Robo 框架,成功完成智源自研具身大脑模型 RoboBrain 2.5 的全流程训练。这一成果首次验证了国产算力集群在具身智能大模型训练中的可用性与高效性,标志着国产 AI 基础设施已具备应对复杂多模态任务的能力。此外,摩尔线程还与小马智行正式宣布达成战略合作。双方将聚焦 L4 级自动驾驶技术落地与规模化应用,围绕小马智行技术核心—— 世界模型及虚拟司机系统的训练与优化展开深度协同,共同探索“AI 算法+AI 算力” 深度融合的合作新范式,以安全可靠的 AI 算力,赋能自动驾驶技术迭代和商业落地。双方将基于摩尔线程 MTT S5000 训推一体智算卡及夸娥智算集群,共同推进小马智行世界模型及车端模型训练的适配与验证。
中国电信近期开源的千亿级星辰大模型,实现了国产 AI 全栈生态的关键突破。此次发布的 TeleChat3 系列包含两大核心模型—— 混合专家架构的
TeleChat3-105B-A4.7B-Thinking 与稠密架构的 TeleChat3-36B-Thinking,其训练全程依托上海临港国产万卡算力池完成,累计消耗 15 万亿 tokens 训练数据,成为国产 AI 发展史上的里程碑事件。技术层面,该系列模型实现从硬件到软件的全链路国产化适配,深度整合华为昇腾生态,包括 Atlas800T A2 训练服务器的硬件支持、昇思 MindSpore 框架的开发环境,以及完整的国产 AI 算力基础设施支撑。
客观来看,英伟达 A100/H100/H800 系列 GPU 仍是全球超大规模前沿模型 (如 DeepSeek-V3) 训练的首选,但国产算力平台已逐步实现突破,可稳定支撑数十亿至千亿参数级模型的全流程训练任务。此前主流大模型高度依赖海外 GPU 的格局正在改变,供应链安全风险得到有效缓解,国产 AI 芯片正从推理侧的“ 单点突破”,迈向训练侧的“ 体系化崛起”。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App