


【TechWeb】12 月 2 日消息,昨日晚间,DeepSeek 发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale,并开源。DeepSeek-V3.2 达到了 GPT-5 的水平,DeepSeek-V3.2-Speciale 在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro。

在发布的技术论文中,DeepSeek 团队提到,过去几个月中出现了一个明显的分化,开源与闭源模型之间的性能差距非但没有缩小、反而似乎在扩大,限制开源模型在复杂任务中能力的三个关键不足。
最新发布和开源的这两款模型 DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale 则是克服了这些不足,成功让开源模型重回全球大模型第一梯队。
强化 Agent 能力,融入思考推理
根据 DeepSeek 官方介绍:
1、DeepSeek-V3.2 的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用 Agent 任务场景。
在公开的推理类 Benchmark 测试中,DeepSeek-V3.2 达到了 GPT-5 的水平,仅略低于 Gemini-3.0-Pro;相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间。
2、DeepSeek-V3.2-Speciale 的目标是将开源模型的推理能力推向极致,探索能力的边界。
V3.2-Speciale 版本是 DeepSeek-V3.2 的长思考增强版,并结合了 DeepSeek-Math-V2 的定理证明能力。该模型具备出色的指令跟随能力、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro。
V3.2-Speciale 模型成功斩获 IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛) 及 IOI 2025(国际信息学奥林匹克) 金牌。
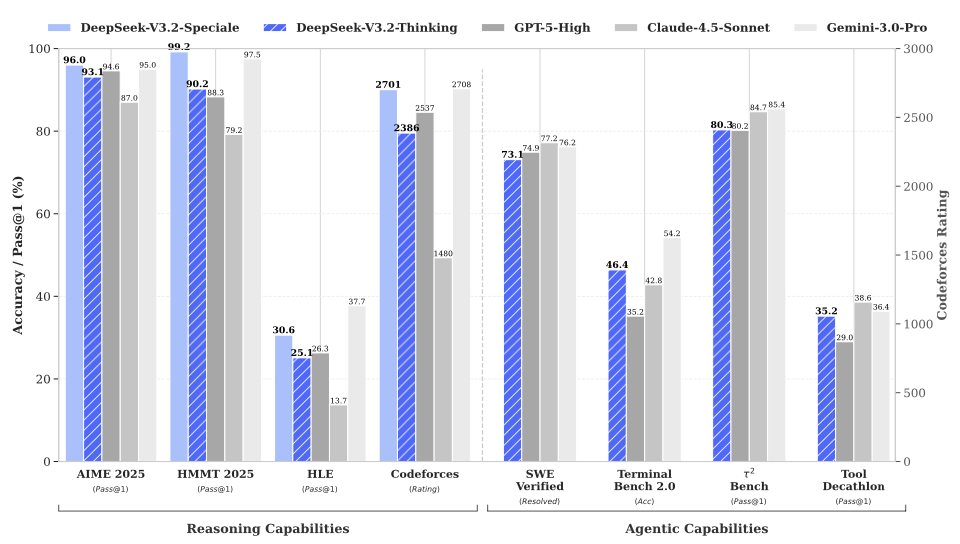
在高度复杂任务上,Speciale 模型大幅优于标准版本,但消耗的 Tokens 也显著更多,成本更高。目前,DeepSeek-V3.2-Speciale 仅供研究使用,不支持工具调用,暂未针对日常对话与写作任务进行专项优化。
当前官方网页端、APP 和 API 用户均可直接体验 DeepSeek-V3.2。API 用户可限时调用体验 DeepSeek-V3.2-Speciale。DeepSeek-V3.2 系列模型已经开源,技术报告同期发布。
三大因素拉大开源模型与闭源模型差距

在技术论文引言中,DeepSeek 团队指出,推理模型的发布标志着大型语言模型发展历程中的一个关键时刻,推动了其在可验证领域整体性能的显著飞跃。然而,在过去几个月中出现了一个明显的分化。虽然开源社区持续取得进展,但闭源专有模型的性能轨迹以明显更快的速度加速提升。因此,开源与闭源模型之间的性能差距非但没有缩小,反而似乎在扩大,专有系统在复杂任务中展现出日益优越的能力。
通过分析,DeepSeek 团队识别出限制开源模型在复杂任务中能力的三个关键不足。
首先,在架构上,对朴素注意力机制的主要依赖严重限制了长序列的效率。这种低效对可扩展部署和有效后训练都构成了重大障碍。
其次,在资源分配方面,开源模型在后训练阶段的计算投入不足,限制了其在困难任务上的表现。
最后,在 AI Agent 方面,与专有模型相比,开源模型在泛化能力和指令遵循能力上表现出明显滞后,阻碍了其在真实部署中的有效性。
为了应对这些关键限制,DeepSeek 团队首先引入了 DSA(DeepSeek 稀疏注意力),一种旨在显著降低计算复杂度的高效注意力机制。该架构有效解决了效率瓶颈,即使在长上下文场景中也能保持模型性能。
其次,开发了一个稳定且可扩展的强化学习协议,允许在后训练阶段进行显著的计算扩展。值得注意的是,该框架分配的后训练计算预算超过了预训练成本的 10%,从而解锁了高级能力。
第三,提出了一种新颖的流程,以在工具使用场景中培养可泛化的推理能力。首先,利用 DeepSeek-V3 方法实施冷启动阶段,将推理和工具使用统一在单个轨迹中。随后,推进到大规模 Agent 任务合成,生成了超过 1800 个任务导向的环境和 85000 个复杂的提示词。这些广泛的合成数据驱动了 RL 过程,显著增强了模型在智能体上下文中的泛化能力和指令遵循能力。
DeepSeek-V3.2 的关键技术突破就包括上述 3 项:引入 DSA 稀疏注意力机制、可扩展的强化学习框架、大规模 Agent 任务合成流程。
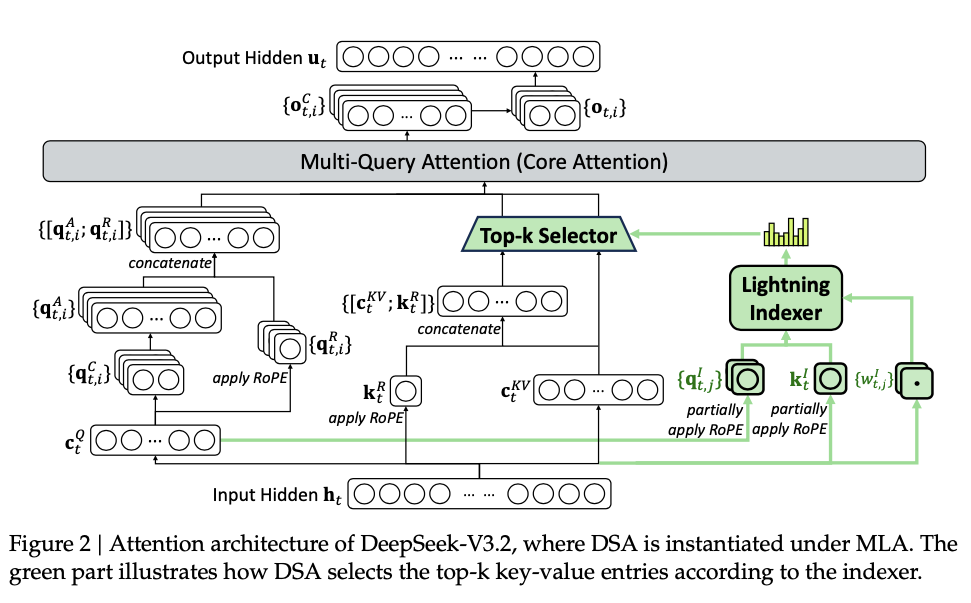
DeepSeek-V3.2 使用与 DeepSeek-V3.2-Exp 完全相同的架构。与 DeepSeek-V3.1 的最后一个版本 DeepSeek-V3.1-Terminus 相比,DeepSeek-V3.2 唯一的架构修改是通过持续训练引入了 DSA 稀疏注意力机制。
DeepSeek-V3.2 保持了与 DeepSeek-V3.2-Exp 中相同的后训练流程,包括专家蒸馏和混合 RL 训练。
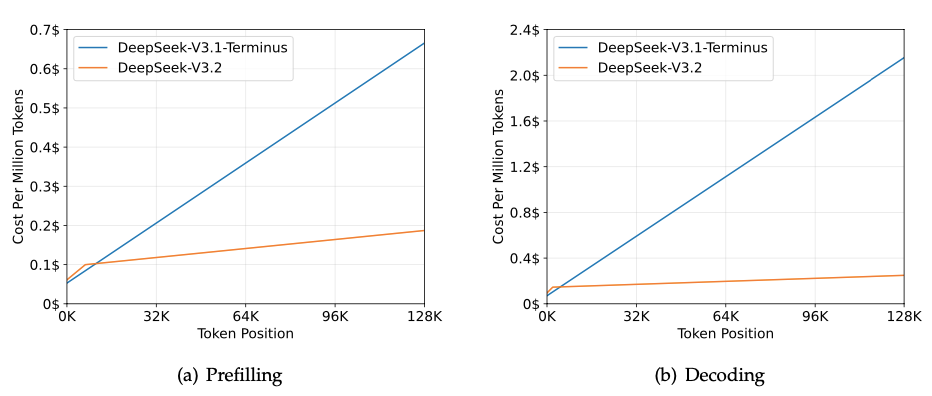
图注:DeepSeek-V3.1-Terminus 和 DeepSeek-V3.2 在 H800 集群上的推理成本
此外,DeepSeek 官方还特意提到:两个月前,其发布了实验性的 DeepSeek-V3.2-Exp,并收到了众多热心用户反馈的对比测试结果。目前未发现 V3.2-Exp 在任何特定场景中显著差于 V3.1-Terminus,这验证了 DSA 稀疏注意力机制的有效性。
基准测试表现,显著提升开源模型的 Agent 能力
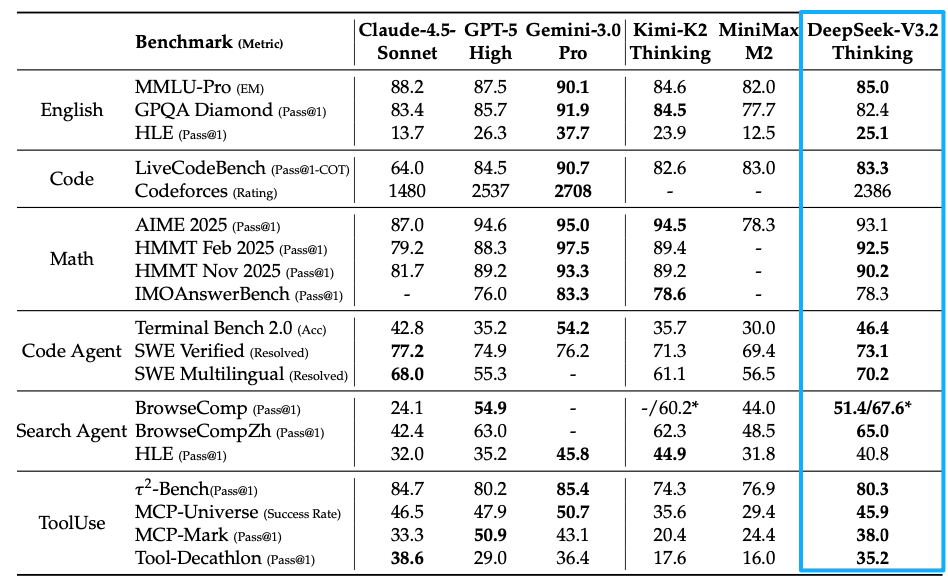
最终,DeepSeek-V3.2 在多个推理基准测试中与 Kimi-k2-thinking 和 GPT-5 取得了相似性能,但略逊于 Gemini-3.0-Pro。
值得注意的是,为了推动开源模型在推理领域的边界,DeepSeek 团队放宽了长度限制,开发了 DeepSeek-V3.2-Speciale。因此,DeepSeek-V3.2-Speciale 实现了与领先闭源模型 Gemini-3.0-Pro 的性能持平。
与 K2-Thinking 相比,DeepSeek-V3.2 以明显更少的输出 tokens 取得了类似的分数。
DeepSeek-V3.2 显著提升了开源模型的 Agent 能力,在长尾 Agent 任务上表现出卓越的熟练度。DeepSeek-V3.2 成为 Agent 场景中极具成本效益的替代方案,显著缩小了开源模型与前沿专有模型的性能差距,同时成本大幅降低。
在代码 Agent 评估中,DeepSeek-V3.2 在 SWE-bench Verified 和 Terminal Bench 2.0 上均显著优于开源 LLM,展示了其在现实世界编码工作流程中的潜力。
DeepSeek-V3.2 的思考模式也增加了对 Claude Code 的支持,用户可以通过将模型名改为 deepseek-reasoner,或在 Claude Code CLI 中按 Tab 键开启思考模式进行使用。
在搜索 Agent 评估中,使用标准的商业搜索 API 评估模型,DeepSeek-V3.2 表现也更优。
在工具使用基准测试上,DeepSeek-V3.2 大幅缩小了与闭源模型之间的性能差距。
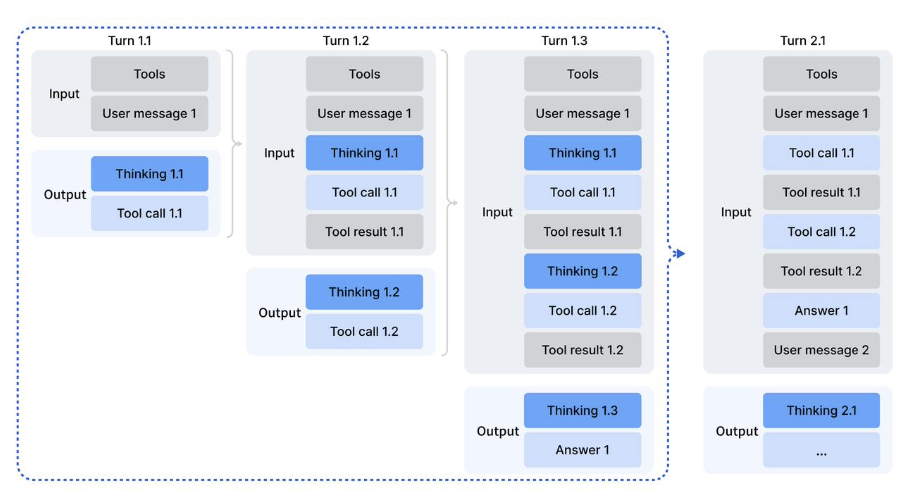
本次 API 更新支持了 DeepSeek-V3.2 思考模式下的工具调用能力。当前在思考模式下,模型能够经过多轮的思考 + 工具调用,最终给出更详尽准确的回答。下图为思考模式下进行工具调用的 API 请求示意图:
技术报告最后也指出了一些当前研究的局限性,包括,由于总训练 FLOPs 较少,DeepSeek-V3.2 的世界知识广度仍落后于领先的闭源模型。在基准测试模型性能时考虑实际计算成本至关重要。寻找串行和并行扩展的最佳组合以最大化效率和可扩展性仍然是团队未来工作的关键方向。

【TechWeb】12 月 2 日消息,昨日晚间,DeepSeek 发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale,并开源。DeepSeek-V3.2 达到了 GPT-5 的水平,DeepSeek-V3.2-Speciale 在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro。
在发布的技术论文中,DeepSeek 团队提到,过去几个月中出现了一个明显的分化,开源与闭源模型之间的性能差距非但没有缩小、反而似乎在扩大,限制开源模型在复杂任务中能力的三个关键不足。
最新发布和开源的这两款模型 DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale 则是克服了这些不足,成功让开源模型重回全球大模型第一梯队。
强化 Agent 能力,融入思考推理
根据 DeepSeek 官方介绍:
1、DeepSeek-V3.2 的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用 Agent 任务场景。
在公开的推理类 Benchmark 测试中,DeepSeek-V3.2 达到了 GPT-5 的水平,仅略低于 Gemini-3.0-Pro;相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间。
2、DeepSeek-V3.2-Speciale 的目标是将开源模型的推理能力推向极致,探索能力的边界。
V3.2-Speciale 版本是 DeepSeek-V3.2 的长思考增强版,并结合了 DeepSeek-Math-V2 的定理证明能力。该模型具备出色的指令跟随能力、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro。
V3.2-Speciale 模型成功斩获 IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛) 及 IOI 2025(国际信息学奥林匹克) 金牌。
在高度复杂任务上,Speciale 模型大幅优于标准版本,但消耗的 Tokens 也显著更多,成本更高。目前,DeepSeek-V3.2-Speciale 仅供研究使用,不支持工具调用,暂未针对日常对话与写作任务进行专项优化。
当前官方网页端、APP 和 API 用户均可直接体验 DeepSeek-V3.2。API 用户可限时调用体验 DeepSeek-V3.2-Speciale。DeepSeek-V3.2 系列模型已经开源,技术报告同期发布。
三大因素拉大开源模型与闭源模型差距
在技术论文引言中,DeepSeek 团队指出,推理模型的发布标志着大型语言模型发展历程中的一个关键时刻,推动了其在可验证领域整体性能的显著飞跃。然而,在过去几个月中出现了一个明显的分化。虽然开源社区持续取得进展,但闭源专有模型的性能轨迹以明显更快的速度加速提升。因此,开源与闭源模型之间的性能差距非但没有缩小,反而似乎在扩大,专有系统在复杂任务中展现出日益优越的能力。
通过分析,DeepSeek 团队识别出限制开源模型在复杂任务中能力的三个关键不足。
首先,在架构上,对朴素注意力机制的主要依赖严重限制了长序列的效率。这种低效对可扩展部署和有效后训练都构成了重大障碍。
其次,在资源分配方面,开源模型在后训练阶段的计算投入不足,限制了其在困难任务上的表现。
最后,在 AI Agent 方面,与专有模型相比,开源模型在泛化能力和指令遵循能力上表现出明显滞后,阻碍了其在真实部署中的有效性。
为了应对这些关键限制,DeepSeek 团队首先引入了 DSA(DeepSeek 稀疏注意力),一种旨在显著降低计算复杂度的高效注意力机制。该架构有效解决了效率瓶颈,即使在长上下文场景中也能保持模型性能。
其次,开发了一个稳定且可扩展的强化学习协议,允许在后训练阶段进行显著的计算扩展。值得注意的是,该框架分配的后训练计算预算超过了预训练成本的 10%,从而解锁了高级能力。
第三,提出了一种新颖的流程,以在工具使用场景中培养可泛化的推理能力。首先,利用 DeepSeek-V3 方法实施冷启动阶段,将推理和工具使用统一在单个轨迹中。随后,推进到大规模 Agent 任务合成,生成了超过 1800 个任务导向的环境和 85000 个复杂的提示词。这些广泛的合成数据驱动了 RL 过程,显著增强了模型在智能体上下文中的泛化能力和指令遵循能力。
DeepSeek-V3.2 的关键技术突破就包括上述 3 项:引入 DSA 稀疏注意力机制、可扩展的强化学习框架、大规模 Agent 任务合成流程。
DeepSeek-V3.2 使用与 DeepSeek-V3.2-Exp 完全相同的架构。与 DeepSeek-V3.1 的最后一个版本 DeepSeek-V3.1-Terminus 相比,DeepSeek-V3.2 唯一的架构修改是通过持续训练引入了 DSA 稀疏注意力机制。
DeepSeek-V3.2 保持了与 DeepSeek-V3.2-Exp 中相同的后训练流程,包括专家蒸馏和混合 RL 训练。
图注:DeepSeek-V3.1-Terminus 和 DeepSeek-V3.2 在 H800 集群上的推理成本
此外,DeepSeek 官方还特意提到:两个月前,其发布了实验性的 DeepSeek-V3.2-Exp,并收到了众多热心用户反馈的对比测试结果。目前未发现 V3.2-Exp 在任何特定场景中显著差于 V3.1-Terminus,这验证了 DSA 稀疏注意力机制的有效性。
基准测试表现,显著提升开源模型的 Agent 能力
最终,DeepSeek-V3.2 在多个推理基准测试中与 Kimi-k2-thinking 和 GPT-5 取得了相似性能,但略逊于 Gemini-3.0-Pro。
值得注意的是,为了推动开源模型在推理领域的边界,DeepSeek 团队放宽了长度限制,开发了 DeepSeek-V3.2-Speciale。因此,DeepSeek-V3.2-Speciale 实现了与领先闭源模型 Gemini-3.0-Pro 的性能持平。
与 K2-Thinking 相比,DeepSeek-V3.2 以明显更少的输出 tokens 取得了类似的分数。
DeepSeek-V3.2 显著提升了开源模型的 Agent 能力,在长尾 Agent 任务上表现出卓越的熟练度。DeepSeek-V3.2 成为 Agent 场景中极具成本效益的替代方案,显著缩小了开源模型与前沿专有模型的性能差距,同时成本大幅降低。
在代码 Agent 评估中,DeepSeek-V3.2 在 SWE-bench Verified 和 Terminal Bench 2.0 上均显著优于开源 LLM,展示了其在现实世界编码工作流程中的潜力。
DeepSeek-V3.2 的思考模式也增加了对 Claude Code 的支持,用户可以通过将模型名改为 deepseek-reasoner,或在 Claude Code CLI 中按 Tab 键开启思考模式进行使用。
在搜索 Agent 评估中,使用标准的商业搜索 API 评估模型,DeepSeek-V3.2 表现也更优。
在工具使用基准测试上,DeepSeek-V3.2 大幅缩小了与闭源模型之间的性能差距。
本次 API 更新支持了 DeepSeek-V3.2 思考模式下的工具调用能力。当前在思考模式下,模型能够经过多轮的思考 + 工具调用,最终给出更详尽准确的回答。下图为思考模式下进行工具调用的 API 请求示意图:
技术报告最后也指出了一些当前研究的局限性,包括,由于总训练 FLOPs 较少,DeepSeek-V3.2 的世界知识广度仍落后于领先的闭源模型。在基准测试模型性能时考虑实际计算成本至关重要。寻找串行和并行扩展的最佳组合以最大化效率和可扩展性仍然是团队未来工作的关键方向。