


- 文 | 科技不许冷
过去两年,全球科技界仿佛被卷入了一场名为 Scaling Law 的宗教狂热。在 OpenAI 和 NVIDIA 的布道下,所有人的目光都锁定在参数量的指数级增长上。从 175B 到万亿参数,从 H100 到 Blackwell,似乎算力就是正义,规模就是真理。投资人和媒体热衷于讨论 GPT-5 何时通过图灵测试,仿佛只要堆足够多的卡,硅基生命就会在云端的数据中心里自然涌现。
然而,在云端算力狂飙突进的背面,物理世界的工程界正面临着一道严峻的高墙。
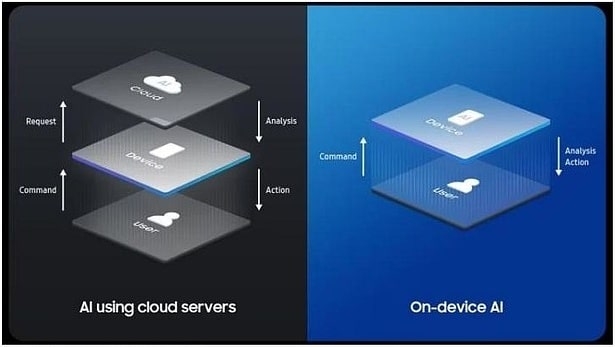
你一定有过这样的体验:对着智能音箱喊一声“ 关灯”,它却还要反应两秒钟,甚至因为 Wi-Fi 波动回你一句“ 网络连接中,请稍后再试”。在那个尴尬的瞬间,所谓的人工智能,表现得还不如一个五块钱的物理开关。
对于这种“ 云端依赖症”,消费者顶多抱怨两句。但对于自动驾驶、工业机器人、医疗急救设备这些“ 要命” 的终端来说,完全依赖云端的“ 超级大脑” 既不现实,也不安全。
想象一下,一辆时速 100 公里的自动驾驶汽车,在识别到前方有障碍物时,如果需要把数据上传到千里之外的云计算中心,等待推理完成后再传回刹车指令—— 光是数据在光纤里跑个来回的物理时间 Latency,就足以酿成一场事故。更别提还有隐私泄露的风险:谁愿意把自己家里的摄像头画面、个人的医疗病历,毫无保留地传到公有云上?
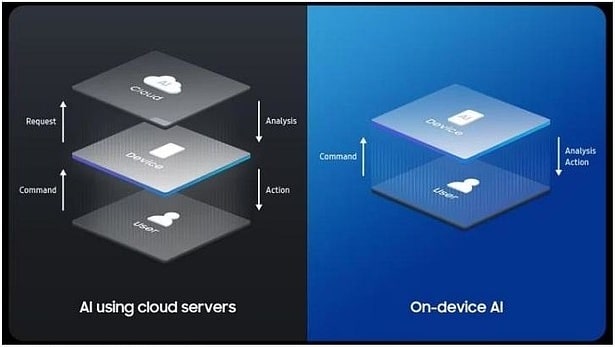
于是,2025 年的技术风向悄然逆转。相比于云端那些遥不可及、每秒烧掉几万美金电费的“ 超级大脑”,工程界开始死磕一个更性感、也更艰难的命题:端侧 AI。
而这并不是一次简单的“ 减配”,而是一场极度反人性的工程恶战。我们要把那个吞噬几千张显卡算力的 AGI,“ 暴力瘦身” 塞进一颗面积仅数平方毫米、功耗仅几瓦的端侧芯片中,同时还要保持它的“ 智商” 不掉线。
今天,我们剥离具体的商业包装,从底层架构视角,来复盘这场发生在芯片与算法上的“ 脑科学” 革命。
当 140GB 撞上几百兆的物理极限
在讨论怎么做之前,我们必须先理解端侧 AI 面临的物理极限,那简直是一种令人绝望的算力悖论。
目前的通用大模型 LLM 是一个十足的“ 富贵病” 患者,它对资源的索取是贪得无厌的。让我们看一组数据:以一个 70B 即 700 亿参数的模型为例,如果我们想要运行它,仅加载模型权重 Weights 就需要占用约 140GB 的显存。这还只是“ 静态” 的占用,模型在推理过程中产生的 KV Cache 更是内存吞噬兽,且随着对话长度的增加呈线性增长。
而在端侧,现实是残酷的。目前主流的车载芯片、智能家居 SoC,甚至是你手中最新的旗舰手机,留给 NPU 的专用内存往往只有几 GB,抠门一点的入门级芯片甚至只有几百 MB。
要把 140GB 的庞然大物,塞进几百 MB 的狭小空间里,这不仅是“ 把大象装进冰箱”,简直是“ 把整个国家图书馆的藏书,强行塞进一个随身携带的公文包里”。而且,用户还提出了一个更变态的要求:你必须在 0.1 秒内,从这个公文包里精准地翻出任意一本书的第 32 页。
这就是端侧 AI 面临的不可能三角:高智商、低延迟、低功耗,三者难以兼得。
为了打破这个悖论,行业目前普遍达成了一个共识:未来的 AI 架构必须是“ 人格分裂” 的—— 也就是“ 云-边-端” 三级分层架构。
单一的云端不够快,单一的端侧不够强。未来的智能系统会像人类的神经系统一样分工:云端是“ 大脑皮层”,部署千亿级参数的 Teacher Model,负责处理极其复杂的、不着急的长尾问题,比如写一篇论文或者规划一次长途旅行。端侧是“ 脊髓” 和“ 小脑”,直接运行在传感器旁边的芯片上,负责高频、实时、隐私敏感的任务,比如语音唤醒、急救避障。
但问题来了:即便只做“ 脊髓”,现在的芯片也常常跑不动。如何在极小的参数规模下保留大模型的涌现能力?这成为了算法工程师面临的头号难题。

三把手术刀下的暴力美学
要在端侧跑通大模型,算法工程师们不得不干起外科医生的活,对模型进行一场精密的手术。这其实是一门关于“ 妥协” 的艺术,在精度和速度之间寻找那个微妙的平衡点。目前的行业主流路径,主要包含三把手术刀。
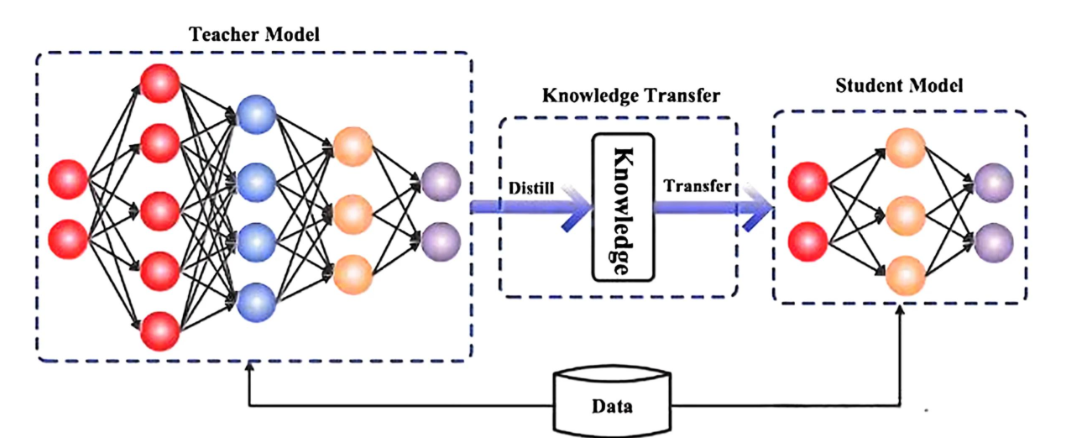
第一把刀是知识蒸馏。 这是端侧模型保持高智商的关键。我们不需要端侧模型去阅读所有的原始互联网数据,那需要海量算力,我们只需要它学会“ 怎么思考”。 所以,工程师让云端的超大模型 Teacher 先学一遍,提炼出核心逻辑、特征分布和推理路径,再“ 传授” 给端侧的小模型 Student。这就像是把一本百万字的学术巨著,由教授浓缩成了一本几千字的“ 学霸笔记”。行业内的一线实践表明,通过这种方式,一个 0.5B 参数的小模型,在特定的垂直场景如座舱控制、家电指令中,其表现甚至能逼近通用的百亿参数模型。它也许不会写诗,但它绝对听得懂“ 把空调调高两度”。
第二把刀是极致量化。 这可以说是工程界最“ 暴力” 的美学。通用大模型通常使用 FP16 甚至 FP32 进行运算,精度极高,小数点后十几位都保留着。但在端侧,每一比特的存储和传输都消耗电量。 工程师们发现,大模型其实极其“ 鲁棒”,砍掉一些精度并不影响大局。于是,他们通过 PTQ 训练后量化或 QAT 量化感知训练,将模型权重从 FP16 直接压缩到 INT8 甚至 INT4。这意味着,原本需要 16 车道的高速公路,现在只需要 4 车道就能跑通。模型体积瞬间压缩了 4 倍以上,推理速度成倍提升。但这其中的难点在于“ 校准”—— 如何在压缩精度的同时,不破坏模型的语义理解能力?这需要极其精细的数学调优,防止某些关键的离群值被误杀。
第三把刀是结构剪枝。 神经网络中存在大量“ 冗余” 的连接,就像人类大脑中有些神经元并不活跃一样。通过结构化剪枝,可以直接剔除那些对输出结果影响微乎其微的参数,从而在物理层面减少计算量。
推倒那堵阻挡数据的内存墙
软件层面的“ 瘦身” 只是第一步,真正的硬仗在于硬件,也就是芯片架构。
如果你去问芯片设计师,大模型最让他们头疼的是什么?他们大概率不会说是“ 计算”,而是“ 访存”。在传统的冯· 诺依曼架构下,计算单元和存储单元是分离的。大模型跑起来时,数据就像早高峰的车辆,在内存 DRAM 和计算单元之间疯狂往返。
这就好比一个厨师切菜速度极快,但他每切一刀,都要跑去隔壁房间的冰箱里拿一根葱。结果就是,厨师大部分时间都在跑路,而不是在切菜。这就是著名的“ 内存墙” 危机。在端侧大模型推理中,甚至有超过 80% 的功耗不是花在计算上,而是花在“ 搬运数据” 的路上。
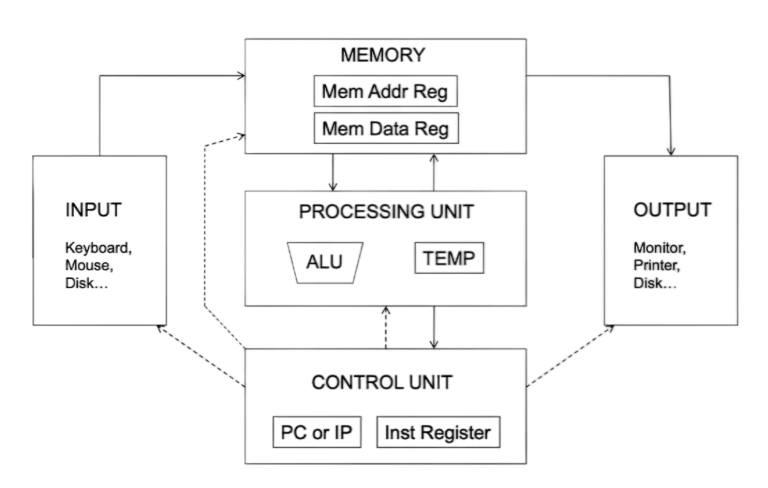
这种尴尬逼出了全新的架构思路:DSA 领域专用架构。
我们观察到,像云知声、地平线这些在端侧深耕多年的硬科技企业,之所以能把芯片出货量做到上亿颗,核心就是不再迷信通用的 CPU 或 GPU 架构,而是针对 Transformer 模型搞起了“ 特权设计”。
首先是存算一体化的探索。既然厨师跑路太累,那就把冰箱搬进厨房,甚至直接把案板装在冰箱门上。通过尽可能拉近存储单元与计算单元的物理距离,甚至在 SRAM 中直接进行计算,极大地减少了数据搬运的“ 过路费”。
其次是异构计算调度。在 SoC 内部,搞起了精细分工:CPU 负责流程控制,DSP 负责信号处理如降噪,而将最繁重的矩阵乘法运算交给高度定制的 NPU。
最关键的是算子硬化。针对大模型核心的 Attention 机制算法,芯片设计团队直接在硅片上“ 刻死” 了加速电路。这种做法虽然牺牲了通用性,但在处理大模型推理时,效率高得吓人。这种“ 算法定义芯片” 的策略,使得端侧方案在处理语音唤醒、指令识别时,能够做到毫秒级响应。这不仅是某一家企业的技术选择,更是整个端侧 AI 芯片行业为了突破摩尔定律瓶颈而达成的“ 妥协后的最优解”。
从全知上帝到熟练工匠
除了在硬件上死磕,另一个更务实的路径是:承认 AI 的局限性,从“ 通用” 走向“ 专用”。
通用大模型往往因为什么都懂,导致什么都不精。它容易产生“ 幻觉”,一本正经地胡说八道。在写科幻小说时这是创意,但在医疗诊断或工业控制中,这是灾难。
这时候,像商汤医疗这类厂商的“ 平台化” 策略就显得非常聪明。面对医疗行业数据复杂、算力受限的痛点,他们没有试图做一个全知全能的“AI 医生”,而是搭建了一个流水线,生产各种专精的“ 特种兵”。
通过将技术封装为“ 模型生产平台”,让医院基于自己的高质量数据,训练出针对特定病种的专用模型。这种思路本质上是将 AI 从“ 全能博士” 变成了“ 熟练技工”。
这种“ 小而美” 的垂直智能体,需要的算力更少,但给出的诊断建议却更靠谱。医生不需要一个能写代码、能画图的 AI,他们需要一个能精准读懂 CT 片子、能快速整理病历的助手。
同样的逻辑也发生在云知声的产业路径中:不在通用大模型的红海里烧钱,而是通过在医疗、家居等垂直领域的深耕,打磨端侧技术与芯片,赚取数据反馈,进而反哺基础研究。
这殊途同归的背后,是整个中国 AI 产业的集体觉醒:不再盲目追求参数规模的“ 大”,而是转向追求应用落地的“ 实”。
最后
在媒体的聚光灯下,大家热衷于讨论 OpenAI 的 Sora 如何震惊世界,或者为 GPT-5 何时通过图灵测试而争论不休,并总将 AGI 与‘ 毁灭人类’ 的宏大叙事绑定。
但在聚光灯照不到的角落,在深圳的华强北,在苏州的工业园,在上海的张江,成千上万的工程师正在做着更枯燥、但或许更具颠覆性的工作:将 AI 的价格打下来,将 AI 的体积缩下去。
从云端到端侧,从通用到垂直,这不仅是技术架构的演进,更是 AI 价值观的回归。
真正的“ 万物智能”,不是每个人都必须要时刻连接到一个全知全能的上帝般的云端大脑。而是万物—— 无论是你手边的空调、车里的仪表盘,还是医院里的 CT 机,都拥有一颗虽然微小、但足够聪明、足够独立的“ 芯”。
当一颗几十块钱的芯片,能跑得动拥有逻辑推理能力的大模型,且不再依赖那根脆弱的网线时,智能时代的奇点才算真正到来。
科技不应该只是服务器里的幽灵,它应该以最硬核、最静默的方式,嵌入我们生活的每一块玻璃、每一颗芯片里,静水流深。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App