


文 | 硅基星芒
长期以来,我们默认生活与网络之间存在一道物理隔离的防火墙。
不过,近几年来,互联网似乎开始不那么“ 安全” 了。
信息安全领域中,有一个叫做“ 实际隐晦性 (Practical Obscurity)” 的概念。
这在生活中并不罕见:如果有人能翻遍你在贴吧的所有发帖、对比你在微博和小红书的发言习惯,就有很大的可能性认出你是谁。
尽管如此,大部分人是没有这个闲情逸致并搭上时间成本来做这件事的。
但如今互联网步入了 AI 时代,情况就变得有所不同。
大语言模型 (LLMs) 的出现,一下子让马甲后那堵防火墙化为齑粉。
还记得上周 Anthropic 指控国产 AI 企业恶意蒸馏,却被用户反问“ 你们是在炫耀能用元数据让用户无法匿名” 的事吗?
就在几天之后,Anthropic 又向全球广播了一个骇人听闻的事实:不用元数据,只要你能用大模型,就可以让匿名无效!
去匿名化的手段:结构化匹配
Anthropic 的安全研究团队又有了新发现。
他们和苏黎世联邦理工学院共同发布了一篇在互联网上极具破坏性的论文:《Large-scale online deanonymization with LLMs》。
称之为“ 破坏性” 其实一点都不过分,因为这篇论文表达的核心观点是:
在互联网上,对于大规模的非结构化文本,通过调用现有的 API 和公开模型,大语言模型只需用最多 4 美元的低廉成本,就可以用极高的准确率将人们的匿名账号与真实身份完全关联。
事实上,去匿名化对于计算机行业来说已经不是一个新的课题。
在 2006 年,当时的流媒体巨头 Netflix 主营业务还是邮寄租赁 DVD。
为了向用户更精准地推荐电影,Netflix 决定举办一场算法竞赛,谁能将现有的电影推荐系统的预测准确率提升 10%,谁就能拿走高达 100 万美元的奖金。
设计算法就需要数据,虽然当时还没有大数据技术,但 Netflix 仍然为此公开了一份庞大的数据集,包含约 50 万名真实用户的观影数据和 1 亿条电影评分记录。
毫无疑问,公开这种隐私数据必须先进行脱敏。Netflix 删除了所有的个人身份信息,如真实姓名、邮箱、地址、信用卡号等,只留下和电影相关的一些信息。
Netflix 也信誓旦旦地向全世界保证:公开的数据中不会包含任何可能识别出个人身份的数据。
在不看电影的人们看来,公开的数据和垃圾并无两样,但最后的结果却超出人们的想象:
两名安全研究人员 Narayanan 和 Shmatikov 在既不攻击 Netflix 服务器、也不使用任何黑客技术的情况下攻破了 Netflix 的防御。
这两位研究员使用了一种叫做链接攻击 (Linkage Attack) 的方法,并引入互联网电影数据库 (IMDb) 作为辅助数据集。
他们敏锐地注意到,很多人在 Netflix 匿名打分的同时,还喜欢在 IMDb 上公开写影评。因此,他们使用爬虫获取了大量公开用户主页,直接拿到了用户的真实姓名、网名、常住地等敏感信息,以及对电影的公开评价和日期。
接下来的步骤就很简单了,拿着这些电影相关的信息,去 Netflix 公开的 1 亿条数据中玩“ 连连看”。
虽然看热门电影的人很多,但每个人看电影的组合和时间轨迹却极其独特,几乎独一无二。
就像是人的指纹一样,凭借着 IMDb 上的公开主页,两位研究员成功实现了匿名评论与用户真实身份的绑定。
也正是在这个时候,灾难降临了。
一旦账号被确定关联,用户的完整观影历史也就彻底暴露,各种隐私信息被迫公开导致 Netflix 被提出集体诉讼,尽管高额的代价实现了庭外和解,但原先设计的第二届竞赛也被永久取消。
这就是最早期的“ 去匿名化” 攻击,看似简单,却奠定了现代信息安全的一个核心概念:
微数据 (Micro-data) 本身就是一种身份标识,这与 Anthropic 防御蒸馏使用的元数据非常类似。
不过,18 年前的这次攻击也存在一个致命的弱点:必须使用结构化数据。
简单地说,攻击者从 IMDb 的公开主页中得到用户观看的确切电影名、打分、时间戳等信息,并将之打包成一个数据包,格式高度标准化,多一条少一条都不行。
只有拿着这种数据包,才能去数据库里“ 连连看”。因此,面对如今我们在社交平台上随意发布的评论,这种手段是没有作用的。
但令人没想到的是,18 年后的 AI 时代,大语言模型带来了技术拐点。
去匿名化的工业级流水线:ESRC 框架
Anthropic 的研究人员发现,现有的大语言模型正好能充当一个永动机般的侦探来玩这局“ 连连看”。
全球范围内,每个用户和 AI 的聊天,组成了海量且杂乱的非结构化数据集,而大语言模型非常善于从这些不经意的闲谈中提取用户的微数据:
点外卖会让它知道你住在哪里,查菜谱会让它知道你爱吃什么,甚至改代码也会让它发现你有用拼音命名变量的坏习惯。
生活中常用 AI 的朋友肯定心知肚明,我们告诉 AI 的信息远不止这些,而如此丰富的信息足以让 AI 将之转化为结构化特征并进行全网匹配。
为了证明大语言模型这种独有的攻击手段能够在百万级别的用户数据库中自动运行,研究团队没有像日常对话一样依赖简单的提示词进行验证,而是专门设计了一套模块化流水线,名为 ESRC 框架。
这个框架的命名由四个阶段的首字母组成:提取 (Extract)、搜索 (Search)、推理 (Reason)、校准 (Calibrate)。
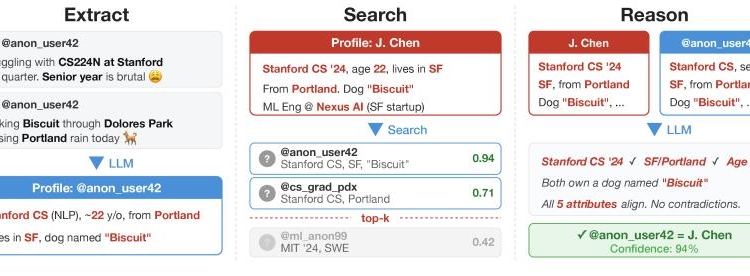
Step 1:提取 (Extract)
日常生活中人们匿名在网络上发表的内容十分随意,语义模糊、无实际意义的文字随处可见,这些都属于非结构化的文本。有的时候,人们看到这些东西自己都不知道自己在说些什么,更别提让模型去理解。
因此,研究人员首先使用了轻量级的大模型对这些文本进行过滤,剔除掉“ 经验+3” 这种无意义的回复以及纯链接等垃圾信息。
随后,过滤后的文本将被发送给高端模型,要求其输出一个用逗号分隔的核心细节列表。
如此一来,一段匿名发送的看起来没什么具体含义的文字就可能变为一段有价值的信息序列,比如 [“24 岁”, ” 学生”, “ 现居北京”, “ 养了一只名叫 coco 的小狗”],类似于 Python 中的列表。
Step 2:搜索 (Search)
有效的匿名信息有了,再加上包含真实身份的数据库,这局“ 连连看” 也就可以开始了。
不过,面对每天上亿个 tokens 和百万用户,如果直接让大语言模型两两比对,时间复杂度就会是 O(N²),给 AI 厂商支付的 API 成本肯定是无法承受的。
因此,Anthropic 的研究团队引入向量检索技术,并调用了 OpenAI 的 text-embedding-3-large 模型作为翻译官。
前面提取出的核心细节列表会被翻译成一个高维度的向量,里面包含成千上万个数字,被称为密集向量。
我们不经意之间告诉 AI 的那些信息,就储存在密集向量中。越是兴趣爱好相似的人,其密集向量在向量空间中就越接近。
而这个时候,Facebook 开发的一个开源工具“FAISS 库” 又能派上用场:它负责计算余弦相似度来寻找那些与匿名信息最匹配的真实身份。
通过这种方式,模型就不必在超大规模的用户池中大海捞针,只需比对与匿名信息最匹配的那一群人即可。
Step 3:推理 (Reason)
需要注意的是,传统的嵌入向量检索技术靠计算余弦相似度只能做到缩小范围,但无法直接实现高精度的匹配,因为依靠向量计算出来的概率进行关联匹配是不可靠的。
相比传统的计算机算法,大语言模型最大的优势就在于能够主动进行“ 推理” 这个过程。
因此,研究人员把与匿名信息最匹配的前 100 个候选真实身份交给顶尖的大语言模型,由它们通过高强度的推理得出结论。
大语言模型既可以寻找相似之处,也可以寻找矛盾之处。
假设有一个候选人与核心信息列表中的绝大部分特征都吻合,例如“24 岁”、“ 学生”、“ 养狗” 等等,但他的 IP 却显示在美国,目标账号活跃时间往往是在凌晨。
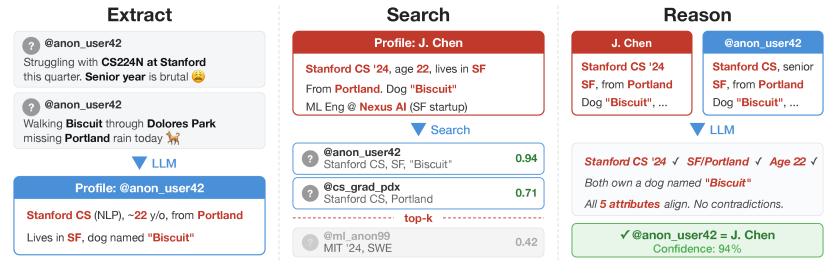
在向量空间中,其匿名发布的信息可能与其真实身份极其接近,但事实截然相反。大语言模型此时就可以像人类一样,利用这些明显的矛盾排除高相似度的错误选项。
Step 4:校准 (Calibrate)
对于真实世界的安全攻击来说,必须遵循一条规律:宁可漏报,绝不误报。因此,校准环节必须解答一个问题:大语言模型已经找到了人,但这个结果是否值得相信?
套用到实际的应用场景中很容易理解:出于好奇心,从一个人匿名发布的内容推测这个人是谁,一旦判断错了不仅前功尽弃,还容易引起不必要的尴尬。
因此,让大语言模型匹配匿名信息与真实身份,要么结果正确,要么没有结果,绝不允许出现错误的匹配。

在大语言模型推理完成后,攻击者就会得到许多匹配结果,一个匿名账号对应一个真实身份,暂且把它记作一对。成千上万对匹配结果中,必然有错有对。
为了解决向量相似度不靠谱和模型推理可能遗漏细微矛盾点等问题,研究团队特意添加了一轮校准机制:
他们又设置了一个价格稍低的模型充当裁判,并让匹配结果中的每一对进行 1v1 的 PK。作为裁判的模型要回答其中哪一对看起来更像是同一个人。
每一轮 PK 后,系统根据结果更新每一对匹配结果的评分。在经过几千次的比较后,最终得到一个极其可靠的置信度排名。
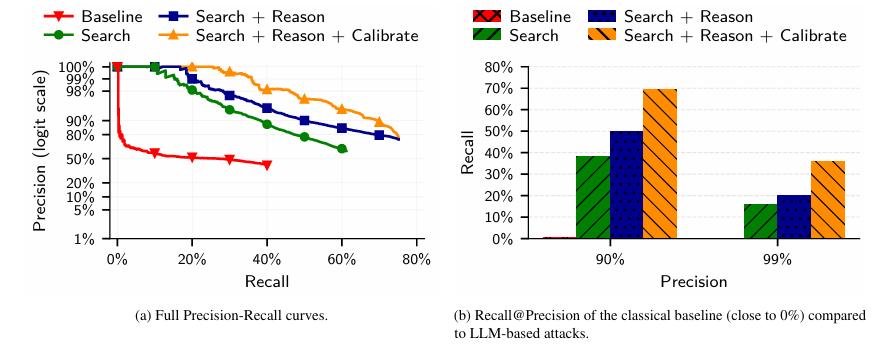
结果显示,这种方法能够极大程度上提高在 99% 以上精确率下的系统召回率,让匹配关系更加可靠。
去匿名化的实验结果:全面击溃
为了评估 ESRC 框架是否有效,Anthropic 的研究团队设计了三个模拟真实世界的场景,结果令人有些害怕。
首先是来自自主 Agent 的降维打击。
研究团队首先构建了一个具备网络搜索功能的大语言模型 Agent,并试图让它将脱敏后的极客论坛账号与真实 LinkedIn 职场身份进行关联。
这个实验与人肉搜索的过程几乎完全一致,攻击者只需要提供脱敏后的极客论坛档案,该 Agent 就能自主生成搜索词、调用搜索引擎并交叉比对从网页中获得的证据。
研究团队设计的准确率要求是 90%,在此基础下该 Agent 竟然成功还原了 67% 的用户身份,耗时只有短短几分钟。
更可怕的是,平均下来每位用户的搜索成本只有 1-4 美元!
这就意味着,大规模、高定制化的“ 人肉搜索” 在经济上已经具备可行性。
接下来有人可能会想,真实的职场身份容易被发现,那如果是不同平台的两个匿名小号呢?
大模型给出的回复是:没有区别。
为了模拟同一用户在不同平台的两个匿名小号,研究团队将 Reddit 用户发布的帖子分为两类:一类是综合电影板块,一类是小众电影板块。
但结果仍然令人惊讶:即便是没有年龄、职业等容易形成强关联的隐私数据,只有主观的电影评价和审美偏好,ERSC 框架也能将两个小号精准关联。
冰冷的数据显示,同一个用户只要在两个匿名小号中共同提到过 10 部电影,被精准关联的概率就已经达到 48.1%。
还有人会说,人的爱好和讨论热点是会变的,过去的账号和现在的新账号压根不相关。
很可惜,模型终究还是成功跨越了时间长河。
研究团队将 1 万名用户的评论以 1 年为期进行划分,一年前的言论作为查询集,一年后的言论作为候选池。
实验证明,即便是完全不同时期的社会新闻和话题,大语言模型还是能见微知著,从写作风格、兴趣甚至是人口统计特征,从包含数千名干扰者的候选池中准确找到用户“ 过去的自己”。
去匿名化的现状:无法防御
无论是 2008 年的 Netflix 事件,还是 Anthropic 研究团队的模拟实验,我们会发现数据规模其实并不大。
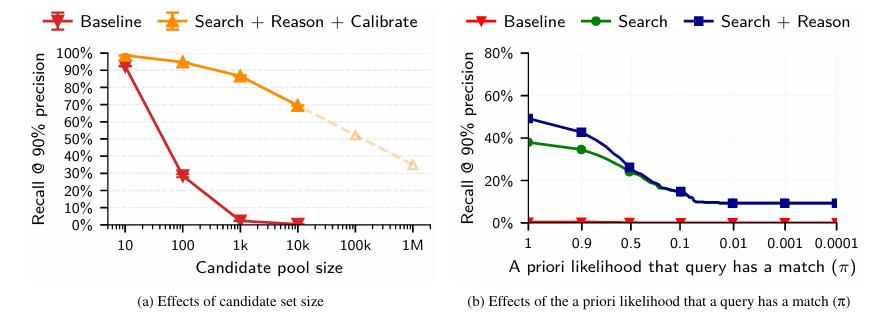
一个最直观且正确的想法是:通过精准匹配实现去匿名化的难度取决于候选池的大小。
若是将候选的真实身份扩充到百万、千万级,采用 ERSC 框架的攻击手段是否还能生效?
传统统计算法显然不行,哪怕是几百人的情况下都会崩溃,召回率直接归零;
但基于大语言模型的 ERSC 攻击不一样,它展现出了恐怖的对数线性衰减特性,即便是百万人,大语言模型仍然能在 90% 精确度的水平下保持 35% 的召回率。
更可怕的是,这种攻击手段,用户无法防御,平台也无法防御。
对于用户来说,传统的隐私保护手段大多是为了结构化数据而设计的。
我们可以把年龄模糊成年龄段,可以把定位服务关掉避免位置信息被获取。
但生活和网络中,一个人总得说话。哪怕是用最高级的文本净化技术来脱敏,大语言模型仍然能从这些非结构化文本和上下文语境中推断出些许特征。
对于平台来说,无法从 API 层面上封杀这种攻击手段。
平台看到黑客针对漏洞进行攻击,可以用防火墙拦截;但如果平台看到用户的请求是“ 帮我看看这两段电影评价哪个写的更好” 呢?
攻击手段恰恰就包含在这些看起来完全正常的用户请求之中,模型提供商根本无法判断调用者是在进行去匿名化攻击还是在正常工作。
至此,网络安全领域的防御成本和攻击成本的非对称性已经被彻底逆转。
结语
以前,我们面对互联网总是会想:我不过是个普通人,谁会闲的没事扒我的马甲?
隐藏在商业世界中的变现逻辑恐怕不会这么想。
如果我们把目光拉回到刚刚过去的春节,国内几家头部大模型平台无一例外地推出了 AI 助手的激励政策。
无论是元宝派的现金红包,还是千问的免费奶茶,几家平台砸下数十亿现金的猛烈营销使得其产品在春节期间的日活数据飙升,但假期一过,留存率却相当惨淡。
按照过往的互联网运营思维来看,这当然谈不上是什么成功的拉新活动。各家的钱都没少烧,ROI 却不见起色,用户薅完羊毛心满意足地转身离去,产品还是没多少人主动用。
但是,看完这篇论文,我却感到细思极恐。
或许,这不是一次失败的拉新营销,而是一场披着春节外衣的大规模微数据收割行动。
回想一下春节假期里人们都用 AI 做了什么?
了解拜年话术、查询年夜饭菜谱、制定旅行规划、订购外卖奶茶、甚至是编写复工请假理由。
这些非结构化的自然语言,在用户看来只是闲聊,在传统算法面前只是几句废话。
但在普遍拥有 ESRC 能力的 AI 公司看来,这些信息就意味着价值,而大语言模型正是发现价值的显微镜。
AI 公司并不需要用户高度留存,相反,只要用户点开对话框,哪怕只用了几分钟聊了几句,大语言模型就能从简短而模糊的需求中精确提取出年龄、常住地、职业、家庭结构、消费能力甚至性格等高价值信息。
在 AI 公司手里,ESRC 框架的攻击手段正是精准描绘用户画像的最强武器。
过去,字节可能需要分析过去一个月用户看过的抖音短视频、腾讯可能要分析用户在微信看过的一千篇历史文章、阿里可能要分析用户在淘宝购买的上百个产品,才能模模糊糊拼凑出用户大概是个什么样的人。
而如今,凭借着大语言模型已经溢出的语义理解和推理能力,仅靠几次不经意之间的对话碎片,AI 就可以轻松在海量数据中完成精准的“ 去匿名化” 定位。
这些被提取出来的高质量用户标签,正是实现精准的广告投流、跨平台数据变现以及未来模型的训练最宝贵的资产。
而我们,没有反抗的余地。
总之,无论如何我们都只能接受一个事实:长期以来,支撑互联网自由表达的匿名机制,在 LLM 面前已经失去了意义。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App