


(本文作者为 TechHorizon,钛媒体经授权发布)
破解算力问题,降低模型所需的存算空间,有很多种途径,是减少训练时算力,还是减少推理时算力?稀疏化、量化、压缩、蒸馏等手段,都是方法之一。只是当前鉴于不同方法的优势特征,各家模型企业及研究机构都会选择不同的策略。
以长上下文任务为例,过去两年,AI 算法团队曾提出要以键值缓存 (KV Cache) 为中心的分离架构设计,即根据不同计算特性将预填充服务器与解码服务器分开,在大 batch size 及队列场景下需要更大的系统内存带宽。简而言之,对于许多推理时任务来说,瓶颈在于内存带宽。
今日,谷歌发布了一项名为 TurboQuant 的算法,这项技术旨在解决上述提及的问题:大模型运行时的内存消耗。其核心是让 AI 在思考和回答问题时,占用少得多的工作内存,同时保持几乎相同的智力水平,甚至速度更快。
根据官方描述,TurboQuant 的推出预计会带来多项利好:模型推理方面,百万 Token 上下文成本会明显下降;向量数据库领域,更容易做到实时索引和亚毫秒查询;边缘 AI 领域,手机和嵌入式设备的上下文推理更现实。此外,该思路同样可扩展到多模态领域的向量压缩。
事实上,就在该技术发布当日,美股存储板块如美光科技、闪迪等应声下跌。近年来,内存 (RAM)、固态硬盘 (SSD)、硬盘驱动器 (HDD) 等存储产品受下游数据中心建设扩张需求的激增,出现了一段时间的供应短缺及价格推高。该市场反应可以理解为,TurboQuant 一旦广泛应用,或将显著影响未来对 AI 推理服务器中内存容量规格的需求判断,重塑相关硬件的成本曲线。
要理解 TurboQuant 的价值,首先要明白大模型在生成文本时是如何工作的。它们并非一次性处理所有信息,而是像人类阅读一样,一个字一个字地生成。在这个过程中,模型需要一个“ 临时记事本” 来记住之前所有对话的内容,以免重复计算。这个“ 记事本” 在技术上被称为键值缓存 (KV Cache)。但问题在于,对话越长,这个“ 记事本” 就越厚,占用的内存就越多。以长文本为例,在处理超长文档或复杂多轮对话时,KV Cache 会迅速撑满昂贵的高性能内存,成为制约 AI 处理速度、推高运行成本的主要瓶颈。
TurboQuant 运用了两个结算的核心算法:PolarQuant 主压缩和 QJL(量化 Johnson-Lindenstrauss 变换) 残差校正,目标是压缩 KV Cache 中的向量。
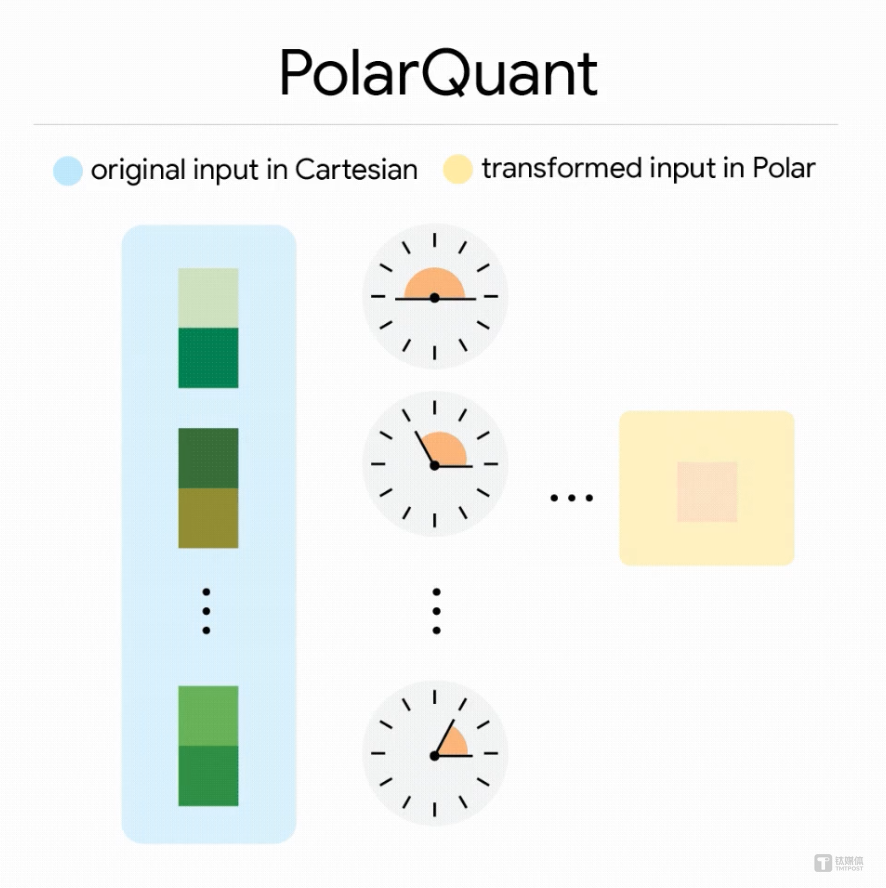
第一步:PolarQuant—— 高质量压缩
传统量化方法类似于用直角坐标系 (东、北方向) 记录一个点的位置。TurboQuant 的第一步,是 PolarQuant,改用极坐标 (角度和距离) 来描述。研究发现,经过特定的数学变换 (随机旋转) 后,高维向量的数值分布会变得非常规律和集中,就像一个固定的圆形网格。这样一来,系统可以预先计算好一套最优的压缩码本,无需针对每次对话进行复杂的校准,实现了在线实时压缩。这一步用大部分比特对数据主体进行了高质量压缩。
第二步:QJL—— 消除隐藏误差
第一步压缩后,会残留微小的误差。如果放任不管,在 AI 计算注意力 (即决定关注对话中哪部分内容) 时,这些误差会累积并导致结果出现偏差。TurboQuant 的第二步创新在于,它用一个名为 QJL 的方法来处理这些残差。QJL 的特点在于,它仅用 1 个比特 (即一个正负号) 来表征残差,并与高精度的原始查询向量结合,最终能实现无偏的内积估计。这意味着,尽管数据被大幅压缩,但 AI 在计算“ 哪些信息更重要” 时,得到的结果依然是准确无误的。
什么是 QJL?简单说,就是一种把高维向量“ 投影” 到低维空间的方法,且能以数学证明保证距离关系不被破坏太多。QJL 把这个投影结果进一步压缩到 1 比特,体积极小,但仍能作为无偏估计器。
根据谷歌官方博客阐述,TurboQuant 带来了接近理论极限的性能提升:

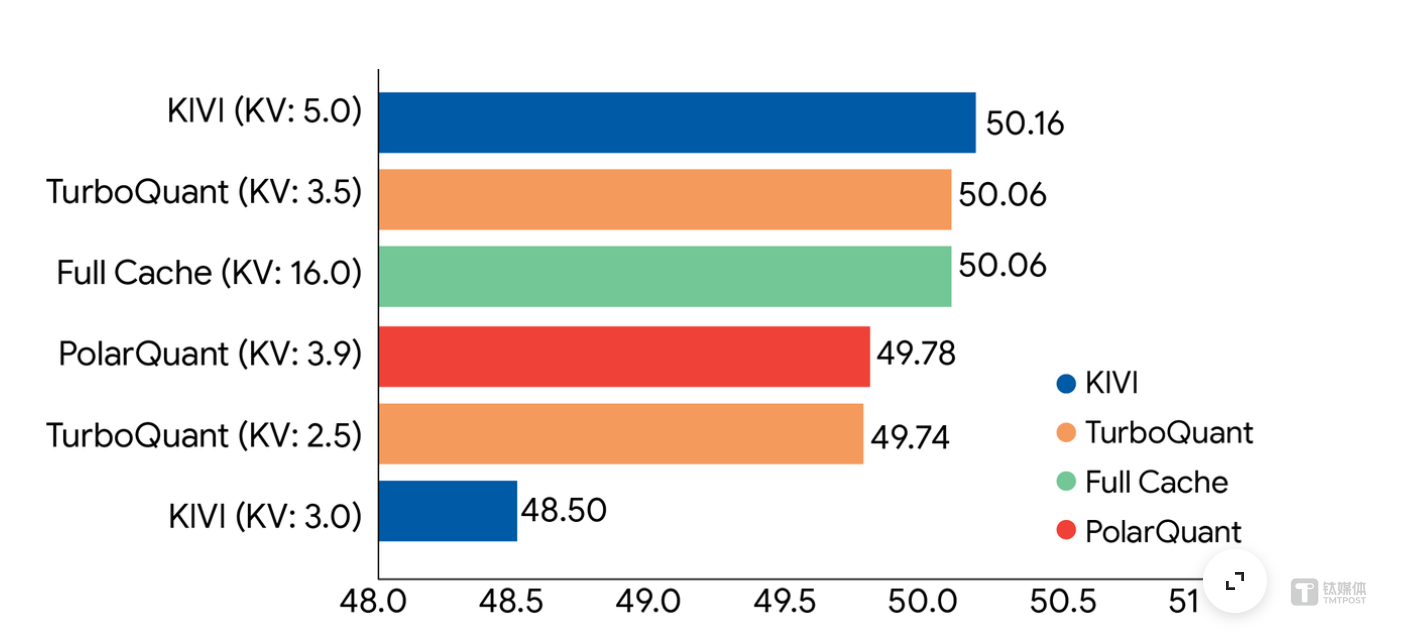
- 极致压缩:可以将 KV Cache 压缩到每通道仅 3 比特,相比传统的 16 或 32 比特存储,减少了至少 6 倍的内存占用。在长上下文测试中,即使压缩后,模型依然能找到隐藏的信息,表现满分。
- 精度无损:在多个标准长上下文基准测试 (如 LongBench、Needle in a Haystack) 上,使用 3.5 比特配置的 TurboQuant,模型性能与使用全精度缓存时完全一致,2.5 比特配置下也只有轻微的性能下降。
- 速度提升:由于需要从内存中读取的数据量锐减,计算速度得到极大提升。在 H100 GPU 上,4 比特 TurboQuant 的注意力核心步骤的速度,比未压缩的 32 比特版本快 8 倍。
TurboQuant 能够以极低的内存占用、近乎零预处理时间和最先进的精度构建和查询大型向量索引。这使得谷歌规模的语义搜索速度更快、效率更高。当然,TurboQuant 的意义远不止于一项实验室突破。据博客所述,向量量化虽然目前主要解决的是 Gemini 等模型中的 KV-cash 瓶颈,但该技术同样适用于需要在高维向量数据库中进行海量搜索的场景 (如现代语义搜索引擎)。
相关论文将在 ICLR 2026 和 AISTATS 2026 发表。
相关链接:https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
相关论文链接:https://arxiv.org/pdf/2502.02617
(本文作者 | 杨丽,编辑 | 杨林)
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App