


(本文作者为 半导体产业纵横,钛媒体经授权发布)
文 | 半导体产业纵横
AI 大模型参数规模持续增长,单卡算力与显存的物理上限,正倒逼 AI 训练集群规模持续扩容。在这场 AI 算力军备竞赛中,网络性能早已成为决定集群算力释放效率的关键。对于超大参数规模的 AI 模型而言,更高的网络带宽,能够直接大幅压缩模型训练的完成周期。
AI 算力释放的技术底座:RDMA
要突破 AI 集群的网络性能瓶颈,RDMA 技术已成为行业公认的解决方案,而这一切的起点,源于 GPU 通用计算时代的通信瓶颈破局。
GPU Direct RDMA 是 2009 年由 Nvidia 和 Mellanox 共同研发的软硬件协同创新技术。当时 GPU 已经从图形渲染转向通用计算 (GPGPU),成为 HPC 的核心加速器。GPU 计算能力虽然在持续提升,但因为集群中不同节点之间的 GPU 间传输数据,仍需要 CPU 负责,通信存在瓶颈,所以 GPU 的计算能力的优势受其拖累不能完全发挥,从而导致集群整体效率不高。NVIDIA 当时清晰地认识到必须解决这个问题,所以开始与合作伙伴 Mellanox 一起探索 GPU 与网卡的直接通信的解决方案 GPU Direct over InfiniBand。后续该技术方案逐渐成熟,并于 2012 年随 Kepler 架构 GPU 和 CUDA 5.0 一起发布,并被正式命名为 GPU Direct RDMA。
在此之前,传统数据中心的数据传输,始终受困于 TCP/IP 架构的原生缺陷。在传统传输方案中,内存数据访问与网络数据传输分属两套语义集合,数据传输的核心工作高度依赖 CPU:应用程序先申请资源、通知 Socket,再由内核态驱动程序完成 TCP/IP 报文封装,最终通过 NIC 网络接口发送至对端。数据在发送节点需要依次经过 Application Buffer、Socket Buffer、Transport Protocol buffer 的多次拷贝,到达接收节点后,还要经过同等次数的反向内存拷贝,完成解封装后才能写入系统物理内存。
这种传统传输方式,带来了三个问题:一是多次内存拷贝导致传输时延居高不下;二是 TCP/IP 协议栈的报文封装全靠驱动软件完成,CPU 负载极高,其性能直接成为传输带宽、时延等性能的瓶颈;三是应用程序在用户态与内核态之间的频繁切换,进一步放大了数据传输的时延与抖动,严重制约网络传输性能。
RDMA(Remote Direct Memory Access,远程直接内存访问) 技术,正是为破解上述痛点应运而生。它通过主机卸载与内核旁路技术,让两个应用程序能够在网络上实现可靠的直接内存到内存数据通信:应用程序发起数据传输后,由 RNIC 硬件直接访问内存并将数据发送至网络接口,接收节点的 NIC 则可将数据直接写入应用程序内存,全程无需 CPU 与内核的深度介入。
凭借这些特性,RDMA 已成为高性能计算、大数据存储、机器学习等对低延迟、高带宽、低 CPU 占用有严苛要求的领域,核心的互联技术之一。而 RDMA 技术协议的标准化,也为不同厂商设备的互联互通提供了统一规范,推动技术从概念走向规模化商用。目前,RDMA 主流实现方案分为三类:InfiniBand 协议、iWARP 协议,以及 RoCE 协议(含 RoCE v1 与 RoCE v2 两个版本)。
随着 AI 模型参数从数十亿级跃升至数万亿级,单 GPU 内存容量持续扩容的同时,服务器间的数据传输效率,已成为决定系统扩展能力、模型训练目标能否实现的关键要素。RDMA 技术的价值也愈发凸显,能否高效访问其他服务器的内存与资源,直接决定了系统的可扩展性,而直接访问远端内存的能力,能直接提升 AI 模型的整体训练性能。正是借助 RDMA 技术,数据才能快速送抵 GPU,最终有效缩短作业完成时间 (Job Completion Time,简称 JCT)。
InfiniBand 和以太网之争
在 AI 智算网络的发展历程中,机柜间互联最早采用成熟的以太网方案,而随着低时延需求的升级,InfiniBand 凭借性能优势快速崛起。作为原生 RDMA 协议的代表,InfiniBand 由 NVIDIA 子公司 Mellanox 主导推动,能提供低于 2 微秒的极低传输时延,同时实现零丢包,堪称 RDMA 领域的性能领导者。
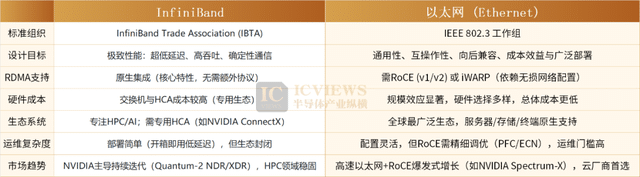
为了将 InfiniBand 的 RDMA 优势迁移至以太网生态,RoCE 协议应运而生。其中 RoCE v1 仅能在二层子网内运行,而 RoCE v2 通过 IP/UDP 封装实现了跨子网路由,大幅提升了部署灵活性,尽管约 5 微秒的时延仍高于原生 InfiniBand,却让以太网具备了支撑 AI 训练高带宽、低延迟需求的能力。
为了撼动 InfiniBand 在 AI 领域的主导地位,2025 年 6 月,博通、微软、谷歌等行业巨头联合推出 UEC 1.0 规范,旨在重构以太网协议栈,使其性能逼近 InfiniBand,标志着以太网对 InfiniBand 发起了全面反击。超以太网联盟 (Ultra Ethernet Consortium,UEC) 明确,UEC 1.0 规范能在包含网卡、交换机、光纤、电缆组成的全网络堆栈层级,提供高性能、可扩展、可互操作的解决方案,从而实现多供应商无缝集成,加速全生态创新。该规范不仅适配以太网与 IP 的现代 RDMA 能力,还支持数百万级设备的端到端可扩展性,同时彻底规避了供应商锁定的问题。
目前,阿里巴巴、百度、华为、腾讯等国内科技企业均已加入 UEC 联盟,共同推进标准落地。除了参与全球标准化建设,国内企业还在同步研发自主可控的横向扩展架构,均以低延迟、零丢包为核心目标,直接对标 InfiniBand 的性能表现。
从产业落地的维度来看,两条技术路线的优劣势十分清晰。RoCE v2 方案依托以太网架构,不仅具备 RDMA 高带宽、低时延的传输性能,还拥有极强的设备互联兼容性与适配性,部署灵活且成本优势显著。相比 InfiniBand,基于以太网的 RDMA 方案,在低成本、高可扩展性上拥有巨大优势。
网络可用性直接决定 GPU 集群算力的稳定性,而 AI 技术的爆发,正推动数据中心交换机向更高速率持续迭代。AI 大模型参数量的指数级增长,带来了算力需求的规模化提升,但大集群并不等同于大算力。为了压缩训练周期,大模型训练普遍采用分布式训练技术,而 RDMA 正是绕过操作系统内核、降低卡间通信时延的核心,目前主流落地的正是 InfiniBand 与 RoCE v2 两大方案。其中 InfiniBand 方案时延更低,但成本偏高,且供应链高度集中于英伟达。根据 Dell‘Oro Group 的预测,到 2027 年,以太网在 AI 智算网络的市场占比将正式超越 InfiniBand。
超节点爆发,高端交换机迎来黄金发展期
随着 AI 大模型参数规模迈入万亿量级,算力需求已从单纯 GPU 堆叠,转向全维度系统架构重构。受单芯片物理功耗密度、互连带宽及内存容量瓶颈制约,算力增长边际效益持续递减。当前研究与工程实践均表明,系统级协同架构 (如高带宽域互联) 是突破单芯片性能上限的主要技术路径,其根本动因在于单芯片物理极限已成为制约算力发展的核心瓶颈。

当模型规模远超单芯片算力与显存容量,传统分布式训练面临通信开销激增、算力利用率大幅下滑等难题。在此背景下,依托高速无损互联技术,将数十乃至上百颗 GPU 芯片逻辑整合为统一计算单元,形成对外等效的 “ 超级计算机”,已成为全球主流 AI 基础设施厂商与科研机构公认的下一代算力架构突破方向。
AI 超节点的爆发,为交换机市场打开全新增量空间。相较于传统服务器,AI 服务器新增 GPU 模组,需通过专用网卡与服务器、交换机实现高效互联,完成节点间高速通信。这使得 AI 服务器组网在传统架构基础上,新增后端网络 (Back End) 层级,单台服务器网络端口数量显著提升,直接拉动高速交换机、网卡、光模块、光纤光缆等全产业链需求。
与此同时,超节点规模化部署,加速网络架构横向扩展 (Scale out)。万卡、十万卡乃至百万卡级别的超大集群组网,催生海量高速交换机需求。随着 AI 模型参数持续扩容,集群规模从百卡、千卡级快速向万卡、十万卡级跃迁,推动组网架构从 2 层向 3 层、4 层持续演进,进一步放大高速交换机市场缺口。
全球 AI 产业的高速发展,让 AI 集群网络对组网架构、网络带宽、网络时延提出了前所未有的严苛要求,也推动以太网交换机这一核心通信设备,朝着高速率、多端口、白盒化、光交换机等方向持续迭代升级。而以太网本身深厚的产业根基与庞大的生态厂商阵容,也让其在 AI 网络中的市场占比拥有持续提升的空间。尽管目前 InfiniBand 凭借低延迟、拥塞控制、自适应路由等机制,仍主导着 AI 后端网络市场,但随着以太网部署方案的持续优化,以及超以太网联盟的生态加速完善,未来以太网方案的市场占比将持续攀升,直接带动以太网交换机的需求增长。
全行业入局,国内外厂商抢滩 AI 交换机赛道
AI 交换机的巨大市场机遇,吸引了全球科技巨头与国内厂商的全面布局,从芯片到整机、从传统设备商到互联网企业,一场围绕 AI 交换机的技术与市场争夺战已然打响。
国际巨头中,英伟达的布局最为激进。其推出的 Spectrum-x 平台,是一套专为超大规模集群场景优化的以太网方案,凭借这一产品,英伟达仅用不到三年时间,便在交换机这一传统 IT 赛道实现了跨界突破。同时,英伟达已将下一代 Rubin AI 平台全面转向 CPO(共封装光学) 架构,并宣布进入量产阶段,让 CPO 从实验室概念,正式成为未来 AI 数据中心的“ 标准配置”。
博通也在去年推出了全球首款 102.4 Tbps 交换机芯片 Tomahawk 6。该系列单芯片提供 102.4 Tbps 的交换容量,是目前市场上以太网交换机带宽的两倍。Tomahawk 6 专为下一代可扩展和可扩展 AI 网络而设计,通过支持 100G / 200G SerDes 和共封装光学模块 (CPO),提供更高的灵活性。它提供业界最全面的 AI 路由功能和互连选项,旨在满足拥有超过一百万个 XPUs 的 AI 集群的需求。
国内传统设备厂商也快速跟进,接连推出旗舰级产品。
华为于 2025 年发布了两款旗舰产品:业界最高密的 128×800GE 100T 盒式以太交换机 CloudEngine XH9330,凭借行业领先的高密端口设计,突破了 AI 集群的规模上限;业界首款 128×400GE 51.2T 液冷盒式以太交换机 CloudEngine XH9230,助力企业打造绿色节能、超大规模的全液冷算力集群。
紫光股份旗下新华三,于 2024 年率先发布 1.6T 智算交换机 H3C S98258C-G,支持全光网络 3.0 解决方案,单端口速率突破 1.6T,整机交换容量达 204.8T,可满足 3.2 万台 AIGC 节点的通信需求。该产品搭载自研智算引擎,时延可低至 0.3 微秒,通过了谷歌等国际客户的验证,成为其 OCS 整机核心供应商。此外,公司还推出了全球首款 51.2T 800G CPO 硅光数据中心交换机,为 1.6T 产品的技术迭代奠定了基础。
锐捷网络完成了基于 CPO 技术的 51.2T 交换机商用互联方案演示,该方案凭借超高集成度、显著的能效提升与可维护性设计,完美适配 AI 训练及超大规模计算集群的高速互联需求,为未来 800G 和 1.6T 网络升级提供了可行路径。其 51.2T CPO 交换机采用博通 Bailly 51.2Tbps CPO 芯片,在 4RU 空间内实现了 128 个 400G FR4 光交换端口,大幅提升了设备端口密度与带宽容量,核心亮点在于通过光引擎与交换芯片的共封装,大幅缩短电互联路径,降低信号衰减与传输功耗。
中兴通讯推出了国产超高密度 230.4T 框式交换机,以及全系列 51.2T/12.8T 盒式交换机,性能处于行业领先水平,已在运营商、互联网、金融等领域的百/千/万卡智算集群实现规模商用。
除了传统交换机厂商,互联网企业也纷纷下场,开启了自研交换机的进程,成为赛道中不可忽视的重要力量。
腾讯早在 2022 年便启动了 CPO 交换机的研发,同年推出并点亮业界首款 25.6T CPO 数据中心交换机——Gemini。该产品集成 12.8T 光引擎,提供 16 个 800G 光接口,剩余 12.8T 交换容量通过面板 32 个 QSFP112 可插拔接口提供。
字节跳动在火山引擎正式上线 102.4T 自研交换机,以此支撑新一代 HPN 6.0 架构,可满足十万卡级 GPU 集群的高效互联需求。该交换机实现全端口 LPO 支持,在 4U 空间内部署了 128 个 800G OSFP 端口。
阿里巴巴在云栖大会展出了自研的 102.4T 国产交换机,率先将 3.2T NPO 技术应用于新一代国产四芯片交换机。该设备单机集成 4 颗 25.6T 国产交换芯片,总交换容量达 102.4T,还可通过升级至 4×102.4T 芯片,平滑演进至 409.6T 平台。
相比线性驱动可插拔光模块 (LPO),近封装光学 (NPO) 能提供更高的带宽密度,同时降低对主芯片 SerDes 性能的要求,更利于产业生态发展;而相比共封装光学 (CPO),NPO 采用标准 LGA 连接器,保留了光模块的开放解耦特性,避免了主芯片与光引擎的绑定,更易被终端用户采纳。
为什么互联网企业要做交换机?
互联网企业纷纷下场自研交换机,并非偶然,而是技术趋势与市场需求的共同驱动。
技术层面,交换机白盒化的发展,为互联网企业自研提供了基础。白盒交换机实现了硬件与软件的解耦,硬件由开放化组件构成,软件则可由用户或第三方自由选择、定制,具备高灵活性、高可扩展性、低采购与运维成本的优势,目前已在互联网厂商与运营商网络中广泛应用,产业生态日趋成熟。锐捷网络作为白盒交换机领域的早期布局者,便与阿里、腾讯、字节跳动等互联网企业深度合作,通过 JDM(联合设计制造) 模式参与下一代交换机研发,2024 年接连中标多家头部互联网客户的研发标,推动白盒交换机在互联网数据中心的规模化部署。而白盒交换机的软硬件解耦特性,大幅降低了自研的技术门槛,也成为大型互联网企业降低建网成本的关键。
市场层面,超大规模数据中心运营商面临着与传统企业完全不同的网络需求:一方面,阿里、腾讯、字节等企业拥有数万甚至数十万级的服务器规模,对网络的可扩展性、可运维性有极致要求;另一方面,AI 训练集群尤其是万卡级 GPU 集群,对网络的低延迟、高带宽有着严苛的定制化需求。传统交换机厂商提供的标准化产品,难以完全匹配这些个性化、极致化的业务需求,最终促使互联网企业走向自研之路。
而自研交换机不仅能深度适配自身业务场景,实现网络能力的定制化优化,又能大幅降低集群建设的总体拥有成本 (TCO),在 AI 算力军备竞赛中,掌握网络底层能力的主动权。
更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App